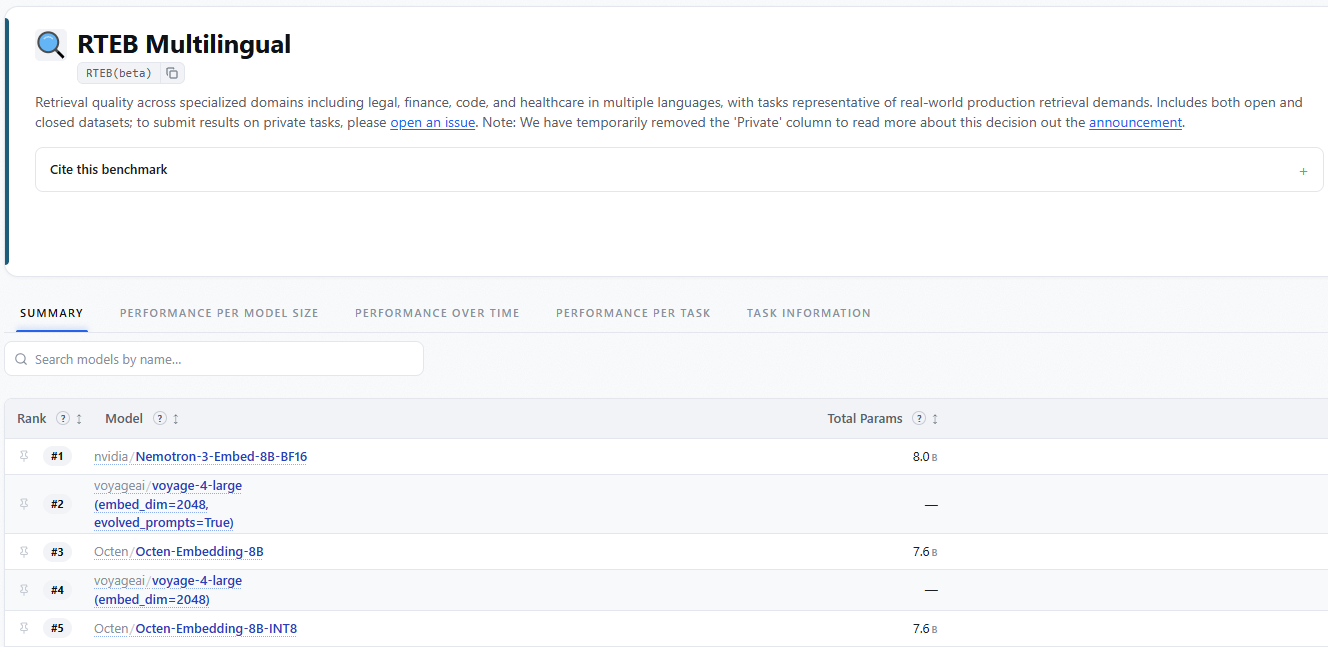
NVIDIA推出Nemotron 3 Embed 8B模型,RTEB检索基准夺冠
7月中旬,NVIDIA正式发布Nemotron 3 Embed系列,包括8B、1B BF16 与 1B NVFP4 三款开源检查点。8B模型在最新检索嵌入基准RTEB上以78.46的平均NDCG@10位居榜首,展示了在跨语言、长序列检索上的领先实力。
NVIDIARTEBNemotron-3-Embed文生检索
•31 阅读•1分钟•前沿
7月中旬,NVIDIA正式发布Nemotron 3 Embed系列,包括8B、1B BF16 与 1B NVFP4 三款开源检查点。8B模型在最新检索嵌入基准RTEB上以78.46的平均NDCG@10位居榜首,展示了在跨语言、长序列检索上的领先实力。
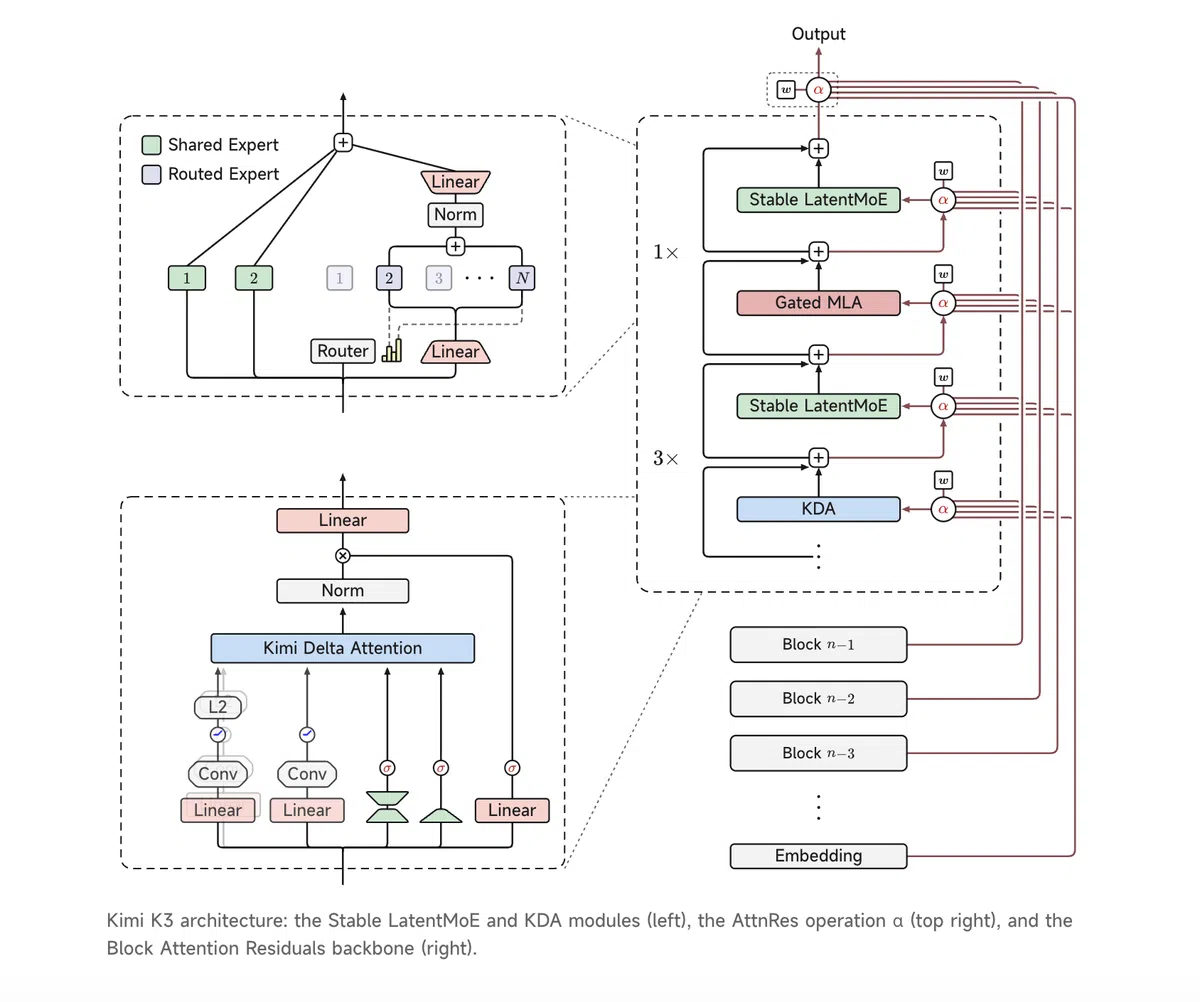


2026年7月9日,Google发布LiteRT.js,将其本地推理库LiteRT编译为WebAssembly,并通过WebGPU、XNNPACK和实验性的WebNN在浏览器中直接运行.tflite模型。该技术在保持隐私的同时,实现了相较于现有网页AI运行时最高60倍的加速。

PrismML今日推出Bonsai 27B,基于Qwen3.6-27B的低比特量化实现,提供1位二进制和三值(‑1,0,+1)两种版本,模型体积分别降至3.9GB和5.9GB,可在笔记本和手机上离线推理,开启大模型本地化新阶段。
斯坦福大学研究团队发布开源系统TRACE,针对代理大模型在任务执行中的重复失误,通过能力对比分析、合成环境训练和LoRA专家路由,实现τ²‑Bench提升15.3分、SWE‑bench Verified达73.2% Pass@1,展示了精准能力强化的强大效能。
Prime Intellect 今日发布 Verifiers v1 0.2.0 版本,将原有环境拆解为任务集、工具链和运行时三大可组合模块,并通过拦截服务器实现实时追踪与奖励安全,支持 OpenAI、Anthropic 等多种对话协议,为大规模代理强化学习提供统一评估平台。
美国密歇根大学团队在《Nature Medicine》发表NeuroVFM,利用Vol‑JEPA在5.24 百万未标注的临床MRI/CT体积上进行自监督学习,突破了传统需要放射报告标签的瓶颈,实现了跨模态、跨设备的高精度诊断与报告生成。
2026年3月7日,Andrej Karpathy 发布开源项目 autoresearch,首次将 AI 代理封装为可验证的循环系统。随后学术界推出 Bilevel Autoresearch 双层循环,实现同一基准上 5 倍的性能提升,标志着机器学习研究进入自动化新阶段。
Thinking Machines实验室在Mira Murati领衔下发布《The Future Worth Building Is Human》报告,提出四大技术路线,主张通过可微调权重、实时交互和去中心化对齐,让企业自行拥有并定制AI模型,以实现人本协同。
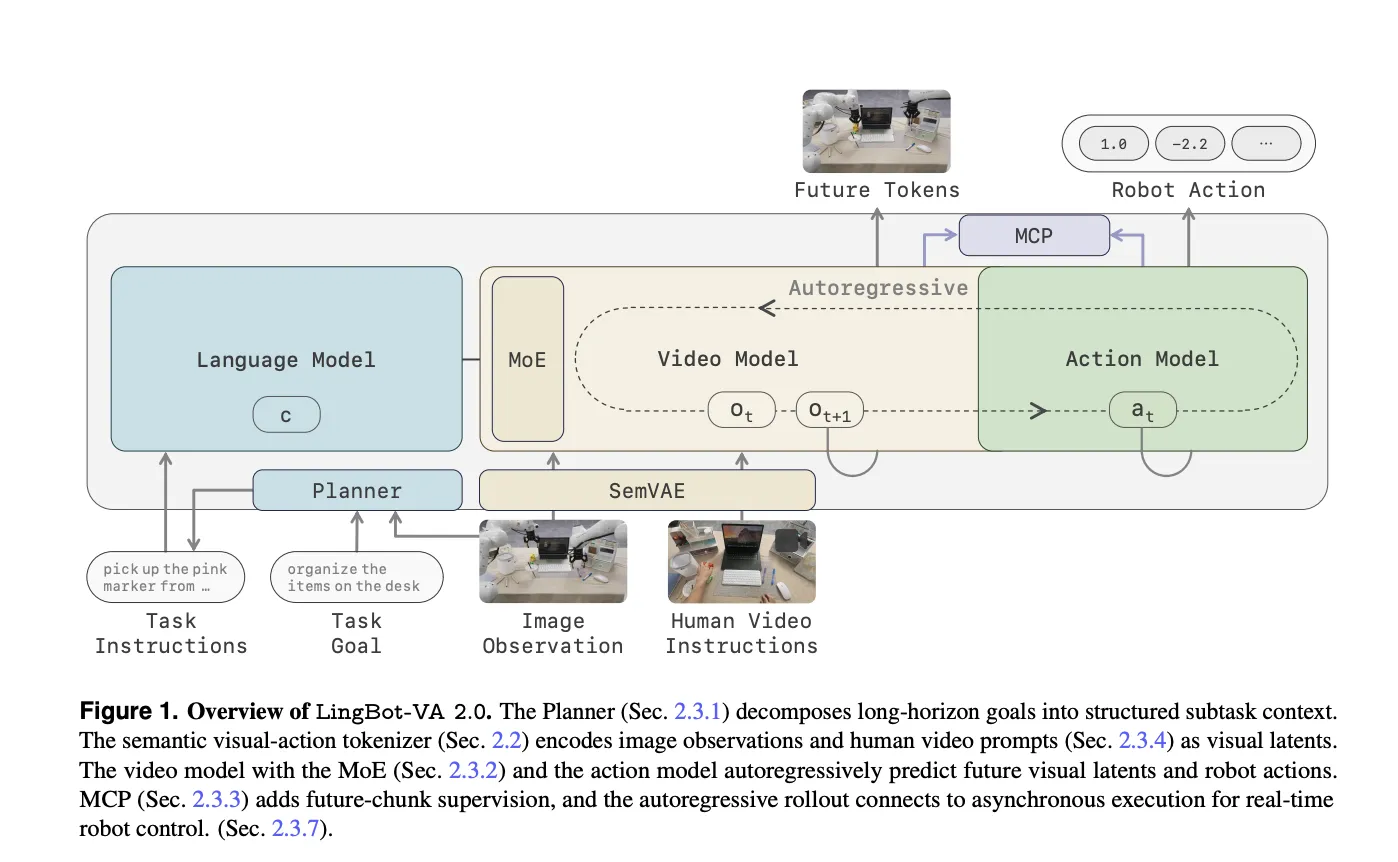

Meta Superintelligence Labs于2026年7月9日正式推出Muse Spark 1.1,并同步开放Meta Model API公开预览。该模型具备1 000 000词的可压缩上下文窗口、零-shot工具泛化及多子代理并行协作,定位为面向Agent任务的多模态推理引擎。
