Olmo Hybrid 7B发布:混合架构实现双倍预训练效率,挑战传统Transformer
•0 阅读•4分钟•前沿
开源OlmoGDNMamba
•0 阅读•4分钟•前沿
背景与趋势
近年来,Qwen 3.5、Kimi Linear、Nvidia Nemotron 3 Nano、IBM Granite 4 等开源大模型纷纷尝试 混合架构——在 Transformer 的自注意力之外加入 RNN 或 Gated DeltaNet(GDN)模块,以降低二次方计算成本并提升长上下文记忆能力。Olmo Hybrid 是首批系统化评估该思路的模型之一。
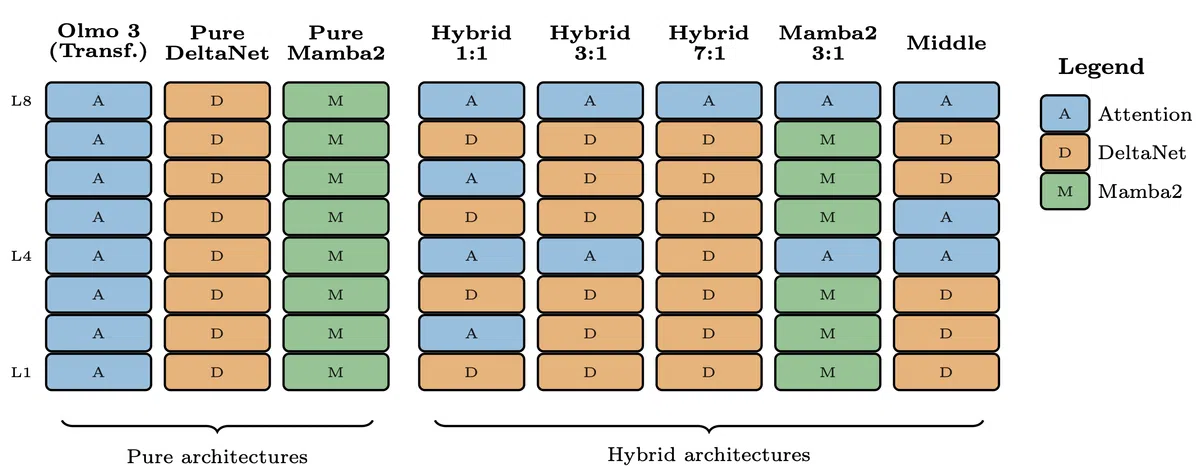
什么是混合模型
- RNN 层:保持隐藏状态,压缩历史信息,避免 KV‑Cache 随 token 增长的 quadratic 开销。
- Gated DeltaNet(GDN):在注意力与递归之间提供门控交互,能够学习注意力难以捕获的序列模式。
- 混合比例:Olmo Hybrid 采用 3:1 的 GDN 与注意力层比例,实验表明该配置在效率与性能之间取得最佳平衡。
“混合模型的表达能力超过其各组成部分的简单相加,这在代码评估等任务上已有理论证明。”——Olmo Hybrid 论文引言
Olmo Hybrid 关键特性
- 模型规模:7 B 参数,提供基础模型、指令模型和即将上线的推理模型三套检查点。
- 预训练效率:相较于 Olmo 3 dense,训练算力提升约 2×,同等算力下可获得更高的 perplexity 与长上下文得分。
- 长上下文表现:在 8K‑16K token 基准上,得分领先标准 Transformer 超过 5%;在表 2 的长上下文实验中尤为突出。
实验与对标
| 架构 | 预训练效率 | 长上下文基准 |
|---|---|---|
| Olmo Hybrid (GDN 3:1) | 2× 提升 | +5% 超越 dense |
| Pure GDN | 1.6× 提升 | +3% |
| 标准 Transformer | 基准 | 基准 |
| Hybrid Mamba2 | 1.3× 提升 | +1% |
实验显示,混合优势在放大到更大模型与算力时仍保持,验证了论文提出的 表达力‑效率正相关 论断。
开源工具链的挑战
- 推理框架:VLLM 等主流库对 GDN 支持仍不完善,需要手动关闭 cascade‑attention 与 CUDA‑graph(
--disable-cascade-attn、--enforce-eager),否则吞吐量下降 30% 以上。 - 数值稳定性:需指定
--mamba_ssm_cache_dtype=fp32才能避免梯度爆炸。当前速度损失抵消了训练阶段的算力节省,预计 3‑6 个月后社区会交付更优化的 kernel。
前景展望
Olmo Hybrid 的发布为 混合模型 在开源生态奠定了可验证的基准,若后续工具链成熟,预计将在 RL、Agentic 任务以及大规模检索中发挥优势。作者 Will Merrill 预测,未来 3‑5 年内,主流前沿模型(包括闭源的 GPT、Claude)采用混合结构的概率约为 50%。
结语
混合架构已从学术概念走向可落地的开源模型,Olmo Hybrid 通过实证证明其在算力效率与长上下文能力上的潜力。随着社区 tooling 的迭代,这类模型有望在生成式 AI 竞争格局中形成新一轮技术分水岭。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。