Physical Intelligence团队推出多尺度记忆系统MEM,让Gemma 3‑4B机器人模型拥有15分钟上下文
背景
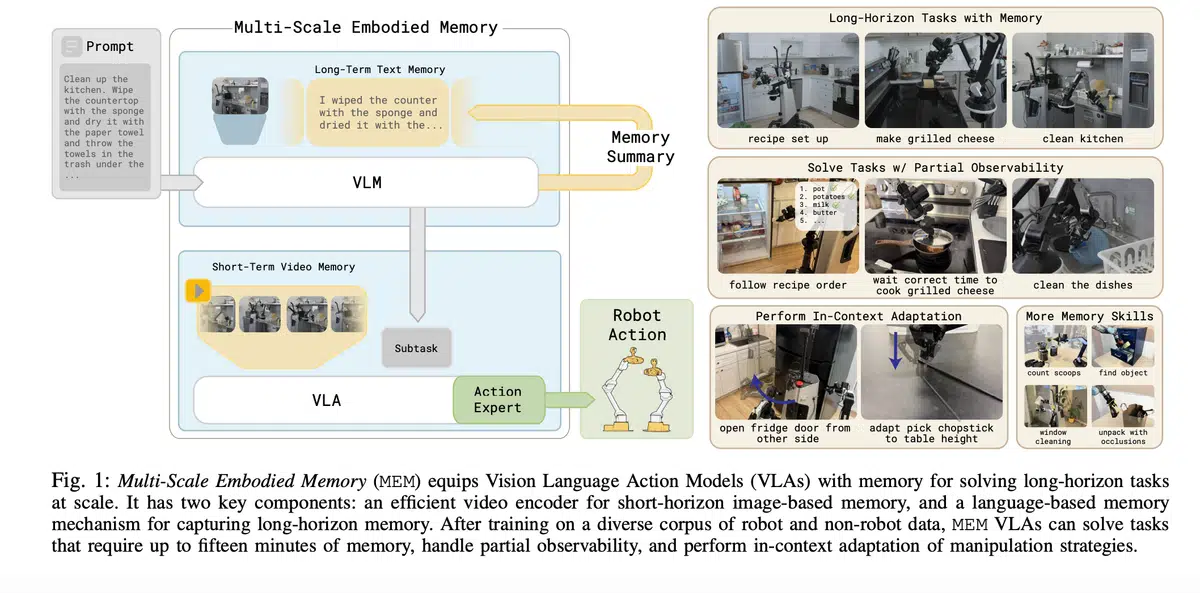
传统的端到端机器人策略,尤其是Vision‑Language‑Action(VLA)模型,往往只能利用单帧或极短的历史信息。这导致在厨房清洁、食谱执行等需要数分钟甚至更长时间的任务上,模型容易出现失误或根本无法完成。为突破记忆瓶颈,Physical Intelligence团队联合斯坦福、加州大学伯克利和MIT的研究者提出了 Multi‑Scale Embodied Memory(MEM),并将其嵌入到基于Gemma 3‑4B的π0.6 VLA中。
MEM 架构
MEM 将机器人记忆划分为两个层次:
-
短期视频记忆:采用空间‑时间可分离注意力(Space‑Time Separable Attention),在每四层插入一次因果时间注意力,显著降低计算复杂度 (O(n^2K^2) → O(Kn^2 + nK^2))。仅保留当前帧的视觉特征进入VLA主干,保持 token 数量与单帧模型相当,实现 380 ms 以内的实时推理。
-
长期语言记忆:利用 LLM 生成的语言摘要压缩过去的语义事件,如“我放了三个碗”。高层策略 (π_{HL}) 维护这段摘要并生成子任务指令,低层策略 (π_{LL}) 根据最近的视觉信息执行具体动作。公式如下:
\pi(a_{t:t+H},l_{t+1},m_{t+1}|o_{t-T:t},m_{t},g) \approx \pi_{LL}(a_{t:t+H}|o_{t-K:t},l_{t+1},g)\pi_{HL}(l_{t+1},m_{t+1}|o_{t},m_{t},g)
实验与成果
团队在真实厨房环境中评估了 MEM‑增强的机器人。关键指标如下:
- 适应性提升:在未知铰链方向的冰箱打开任务中成功率提升 62%。
- 细粒度操作:在可变高度的筷子拾取任务中提升 11%。
- 长程任务:成功完成 15 分钟的“配方准备”与“厨房清洁”两大任务,记忆缺失的基线模型几乎全部失败。
- 算力效率:单卡 NVIDIA H100 下,视频编码器可一次处理 16 帧(约 1 分钟),仍保持实时推理门槛。
“MEM 的核心在于用语言压缩长期语义,用视觉捕捉短期细节,两者相辅相成,使机器人拥有类似人类的工作记忆。”——论文作者之一
影响与展望
MEM 的设计思路为机器人长期自治提供了可行路径。通过将大模型的语言理解能力与高效视频编码相结合,系统在不牺牲实时性前提下实现了 15 分钟 级别的上下文记忆,这可能推动厨房助理、仓储分拣以及家庭清洁等场景的商业落地。未来工作包括:
- 将 MEM 与更大规模的基础模型(如 GPT‑4‑Turbo)对齐,以提升语言摘要的细腻度;
- 探索跨模态记忆共享,让机器人在视觉、触觉和语言之间实现信息互补;
- 优化硬件加速,进一步压缩视频编码的延迟,争取突破 200 ms 实时门槛。
结语:MEM 为机器人记忆体系注入了“双尺度”创新,展示了在保持算力可控的前提下,实现长时程任务的可行性。随着开源模型与专用硬件的持续迭代,类似 MEM 的记忆框架有望成为下一代通用机器人系统的标准组件。