AI评测大变革:从静态题库到动态智能体
•4 次浏览•3分钟•视野
行业趋势AI评测智能体动态评估大模型
Jesus Rodriguez••4 阅读•3分钟•视野
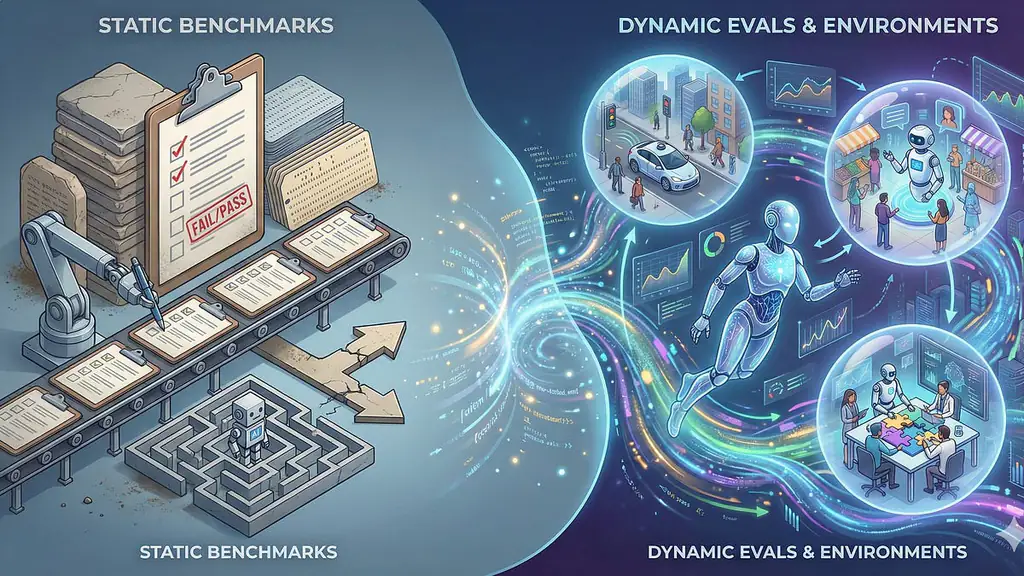
背景:旧基准的局限
过去几年,MMLU、GSM8K 等静态 benchmark 成为了衡量大模型能力的“单元测试”。这些数据集本质上是固定的问答列表,类似于数字化的 SAT 或 StackOverflow。模型只要在权重中记住答案,即可在指标上取得高分,导致 “分数膨胀”——模型看似表现卓越,却缺乏真实任务的迁移与推理能力。
从 Chatbot 到 Agent 的转型
- Chatbot 阶段:模型主要负责下一个 token 的预测,输出往往局限在一次性答案。
- Agent 阶段:模型被视作数字员工,需要在环境中观察、决策、执行,并完成跨步骤的工作流。例如,修复代码库中的 bug、在企业内部调度资源、完成端到端的客户服务。
这种从 “问答‑答案” 向 “观察‑行动” 循环的转变,要求评测体系也随之升级。
动态评估的核心要素
- 交互式环境:提供可编程的仿真平台(如 OpenAI Gym、LangChain‑Agent)让模型在真实或近真实的情境中操作。
- 长期目标:评测不再只看单步准确率,而是关注多步骤任务完成度、资源利用率和错误恢复能力。
- 可解释性与可靠性:记录模型的决策路径,评估其是否产生幻觉或错误依赖。
- 人机协同指标:衡量模型与人类合作时的效率提升,而非单独的自动化水平。
为什么现在必须变革
- 数据饱和:MMLU、GSM8K 等基准已出现 “记忆化” 现象,模型在这些测试上接近满分,但在真实业务场景中仍频繁出错。
- 商业需求:企业希望模型直接投入生产环境,而不是仅作为问答工具,需要可靠的行为验证。
- 学术驱动:研究者逐渐聚焦于 “reasoning‑through‑action”,即通过行为序列展现推理过程,这要求评测能够捕捉过程细节。
未来展望
- 统一评测平台:业界正在探索类似 AI‑Gym 的统一框架,提供跨任务、跨领域的动态评估套件。
- 标准化指标:如 Task Success Rate、Step Efficiency、Hallucination Rate 等将成为新基准的核心指标。
- 开源与闭源协同:虽然评测平台多为开源,但大型云服务提供商可能会推出专属的高保真仿真环境,形成新的竞争格局。
观点:评测体系的升级不仅是学术的进步,更是 AI 商用落地的关键门槛。只有在动态、真实的环境中检验模型,才能真正从“书本智能”迈向“街头聪明”。
随着 2026 年进入下半年,更多企业和实验室已经开始在内部部署 Agent‑Level 的评估流程。我们预计,未来一年内,至少会有三大主流 benchmark 公开其动态评测版本,标志着 AI 评测进入 新纪元。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。