NVIDIA推出PersonaPlex-7B:首个实时全双工语音对话模型
•9 次浏览•4分钟•前沿
NVIDIALLMPersonaPlex全双工语音Transformer
•9 阅读•4分钟•前沿
模型概览
NVIDIA 近期开源了 PersonaPlex-7B‑v1,一款 7 B 参数的全双工(Full‑Duplex)语音‑到‑语音对话模型。该模型将传统语音助手的 ASR → LLM → TTS 三段流水线合并为单一 Transformer 网络,实现了 实时听说、重叠发言 与 快速回合切换,极大降低了端到端延迟。
技术创新
- 双流结构:模型同时维护用户语音流与代理语音流,共享同一状态,使得系统在输出语音的同时仍能继续捕获用户的中断或重叠。此设计直接借鉴了 Kyutai 的 Moshi 框架。
- 混合提示(Hybrid Prompting):
- 声纹提示:以音频 token 序列编码说话人的音色、语调与风格。
- 文本提示:描述角色背景、组织信息及对话场景。
- 系统提示:最多 200 token,进一步约束业务名称、预算等上下文。
- Helium 语言模型骨干:在 Moshi 权重之上加入 Helium 作为语义理解层,提升模型在未见情境下的推理能力。
- Mimi 编码/解码器:结合 ConvNet 与 Transformer 的混合结构,将 24 kHz 连续音频离散化为 token,并在同一网络中同步生成文本与音频 token。
训练数据与评估
数据来源
- 真实对话:来自 Fisher English Corpus 的 7,303 通电话(约 1,217 小时),经 GPT‑OSS‑120B 标注生成多层次 persona 提示。
- 合成对话:
- 助手场景 39,322 条(约 410 小时)
- 客服场景 105,410 条(约 1,840 小时)
- 合成文本使用 Qwen3‑32B 与 GPT‑OSS‑120B,语音合成采用 Chatterbox TTS。
基准测评
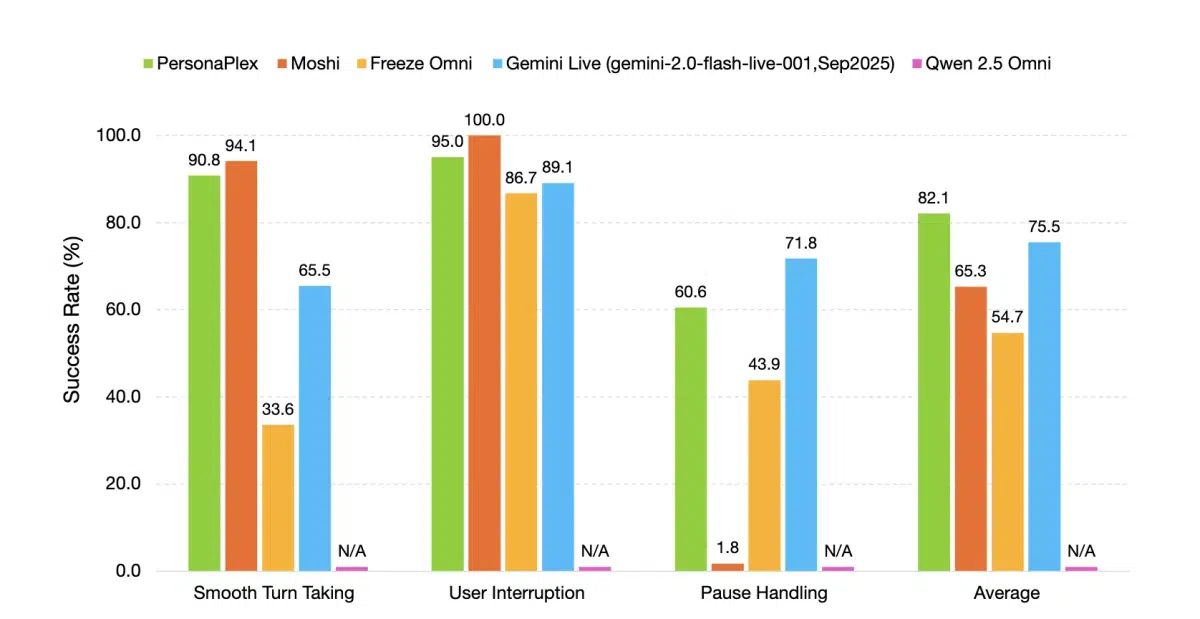
- FullDuplexBench 与 ServiceDuplexBench 两大基准,评估指标包括 Takeover Rate (TOR)、延迟、背道(Backchannel)以及任务遵循度。
- 在顺畅回合切换上 TOR 达 0.908,延迟 0.170 秒;在用户中断场景 TOR 达 0.950,延迟 0.240 秒。
- 声纹相似度(WavLM TDNN)为 0.650,显著优于多数开源与闭源对手。
业界意义
PersonaPlex 的出现标志着 全双工语音交互 从研究原型迈向可商用化阶段。它不仅能让智能音箱、客服机器人实现自然的“人机对话”交叉发言,还为 多角色多业务 场景提供了统一的声纹与角色控制接口。随着模型代码在 MIT 许可下开放、权重采用 NVIDIA Open Model License,生态合作伙伴可以在本地或云端快速部署,推动语音 AI 向 低延迟、可定制、高可用 的方向演进。
“全双工对话是下一代人机交互的必然形态,PersonaPlex 为此提供了完整的技术栈。” – NVIDIA 研究团队
如需获取模型权重、代码及详细技术报告,请访问 NVIDIA 官方研究页面。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。