NousResearch发布NousCoder-14B:基于Qwen3-14B的竞技编程模型,Pass@1达67.9%
•9 次浏览•3分钟•开源
Nous ResearchQwen3-14BLiveCodeBenchRL开源模型
•9 阅读•3分钟•开源
模型概览
NousCoder-14B 是一款专为竞技编程设计的语言模型,底座采用 Qwen3-14B,通过 RL(执行式强化学习) 进行后训练。模型规模保持 14 B 参数,支持最高 81,920 token 长上下文,能够一次性处理复杂的题目描述与大量测试用例。
基准成绩
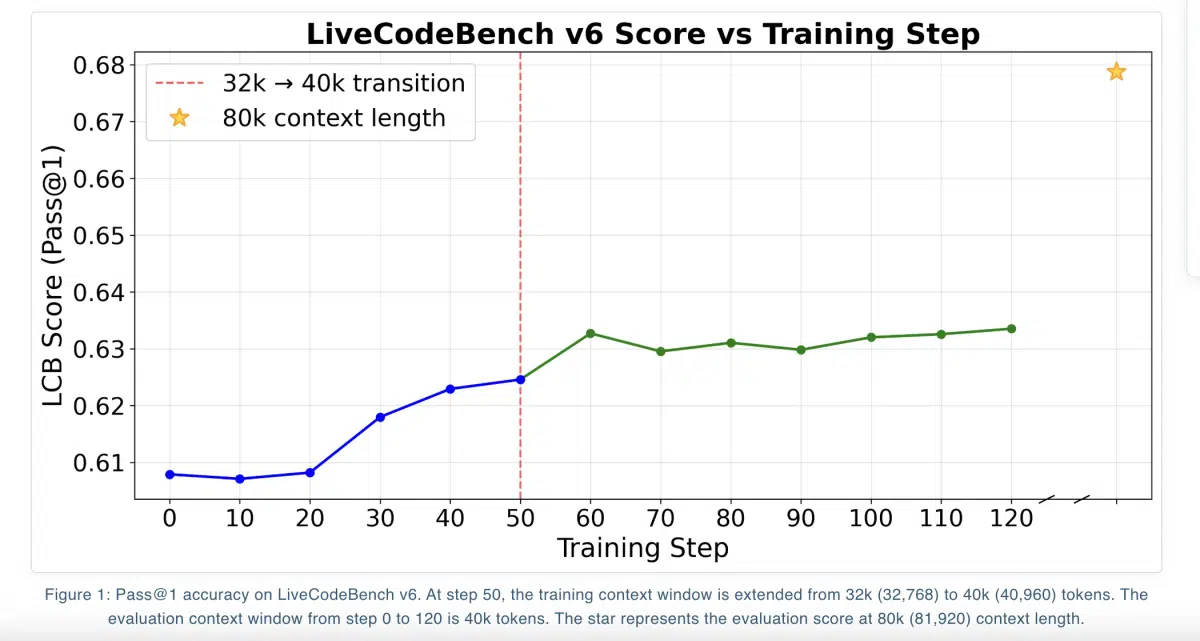
- LiveCodeBench v6(454 道题,2024‑08‑01 至 2025‑05‑01)
- Pass@1 = 67.87%
- 相比 Qwen3-14B 基线的 60.79% 提升 7.08%
- 在不同上下文长度下的表现:
- 81,920 token:DAPO 最高 67.87%
- 40,960 token:三种目标均约 63%
训练数据与 RL 框架
- 数据来源(共 24k 条)
- TACO Verified
- PrimeIntellect SYNTHETIC‑1
- 2024‑07‑31 前的 LiveCodeBench 题目
- 奖励设计
- ✅ 全部测试用例通过 → +1
- ❌ 任何错误、超时(>15 s)或超内存(>4 GB) → -1
- 执行环境
- 使用 Atropos 框架构建 RL 环境
- Modal 提供自动扩缩的沙箱容器,实现安全、并行的代码执行
- 推理‑验证流水线异步化,保持训练循环以推理为瓶颈而非验证
GRPO 及其变体
| 目标 | 关键特性 | Pass@1(81.9k) |
|---|---|---|
| DAPO | 令牌级剪裁、动态抽样、优势归一化 | 67.87% |
| GSPO | 序列级重要性比率 | 66.26% |
| GSPO+ | 序列层面梯度重新缩放 | 66.52% |
三者均基于 Group Relative Policy Optimization(GRPO),不需要单独的价值模型,优势通过同组奖励的均值与标准差归一化得到。
长上下文与过滤策略
- 训练采用 迭代上下文扩展:先在 32k token 上微调,再扩展至 40k token。
- 推理时使用 YaRN 将上下文延展至 81,920 token。
- 超长过滤:若生成代码超过最大上下文,直接将其优势置零,防止模型因惩罚而倾向生成短代码,保持解题质量。
开源发布与行业意义
- 权重、数据以及完整的 RL 管道代码均在 Hugging Face 上以 Apache 2.0 许可证公开,方便学术复现与商业落地。
- 通过执行式 RL 实现的显著性能提升,为后续 代码生成、自动评测 与 AI 辅助编程 提供了可参考的技术路线。
- 该模型的成功展示了 大模型长上下文 与 高效奖励信号 的结合潜力,预示着未来在更复杂的程序合成任务中,开源社区有望继续缩小与闭源 SOTA 的差距。
NousCoder-14B 的出现不仅是一次模型性能的跃迁,更是开源生态在专业编程领域的一次重要里程碑。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。