NVIDIA发布NeMo Agentic检索管线 实现跨场景领先
•0 阅读•4分钟•前沿
NVIDIANeMo RetrieverOpus 4.5nemotron-colembed-vl-8b-v2ViDoRe
•0 阅读•4分钟•前沿
背景与动机
在企业级文档检索场景中,仅靠语义相似度已难以满足复杂查询的需求。NVIDIA NeMo Retriever团队指出,真实业务往往涉及视觉布局解析、深度逻辑推理等多步骤推理过程,单一的稠密检索模型难以兼顾速度与推理深度。为此,他们设计了一套 Agentic 检索循环,在 LLM 与检索器之间形成主动、迭代的交互,以实现更高的检索准确率和跨任务适配能力。
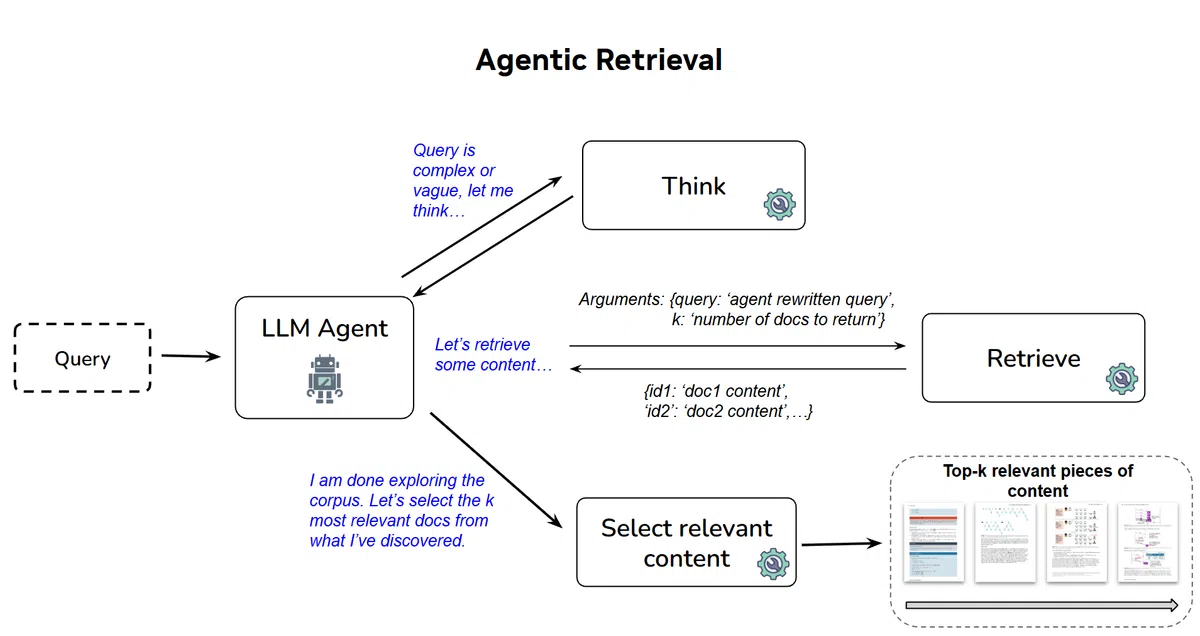
Agentic 检索循环
- ReACT 架构:采用思考(think)→检索(retrieve)→评估(evaluate)→输出(final_results)的闭环流程。
- 动态查询生成:LLM 根据已发现的信息实时重写查询,持续逼近目标答案。
- 多步拆解:将复杂多段查询拆分为若干子查询,各自完成后再综合结果。
- 安全回退机制:当步骤超限或上下文长度受限时,系统自动切换至 Reciprocal Rank Fusion (RRF),融合所有检索轨迹的排序得分,确保结果不至于完全失效。
"Agentic 检索让 LLM 的推理能力与检索器的规模优势相互补足,形成了超越单一模型的协同效应。"
加速与规模化设计
传统的 LLM‑Tool 调用需要通过 Model Context Protocol (MCP) 服务器进行网络通信,导致显著的延迟并增加部署复杂度。NVIDIA 将 MCP 替换为 进程内单例检索器:
- 一次性加载:模型与语料库嵌入仅在首次调用时加载至 GPU,后续请求共享同一实例。
- 线程安全:使用可重入锁保护检索接口,支持多并发 Agent 任务而无网络序列化开销。
- 效能提升:实验表明,单例方案将整体吞吐率提升约 2.5 倍,GPU 利用率亦大幅提升。
跨基准通用性
| 基准 | 方案 | NDCG@10 | 备注 |
|---|---|---|---|
| ViDoRe v3 | NeMo Agentic (Opus 4.5 + nemotron-colembed-vl-8b-v2) | 69.22 | #1,显著领先密集检索 |
| ViDoRe v3 | Dense Retrieval (nemotron-colembed-vl-8b-v2) | 64.36 | 基线 |
| BRIGHT | NeMo Agentic (Opus 4.5 + llama-embed-nemotron-reasoning-3b) | 50.90 | #2,展示在推理密集任务上的竞争力 |
上述结果表明,Agentic 流程能够在视觉丰富文档和深度推理任务之间自适应调节检索策略,避免了针对单一数据集的手工调参。
成本与未来方向
- 时延:在单卡 A100 上,ViDoRe 场景平均每条查询耗时约 136 秒,输入 token 约 760k,输出 token 约 6.3k。
- 费用:相较于纯稠密检索,Agentic 流程的计算成本更高。
- 下一步:团队计划通过 模型蒸馏 将 Agentic 推理模式迁移至更小的开源模型,以在保持精度的同时显著降低延迟和费用。
如何自行构建
- 选择模型:推荐使用 Opus 4.5(或同等级闭源模型)搭配 nemotron‑colembed‑vl‑8b‑v2 作为基础嵌入。
- 部署单例检索器:在 Python 环境中通过
SingletonRetriever类实例化,并确保 GPU 上的嵌入一次性加载。 - 实现 Agent Loop:依据 ReACT 思路,实现
think -> retrieve -> evaluate -> final_results四步工具函数,加入 RRF 作为后备。 - 调优:在目标数据集上监控 NDCG@10 与查询时延,依据需求在开放模型(如 gpt‑oss‑120b)与闭源模型之间权衡。
通过上述步骤,开发者即可在自有业务中复现 NVIDIA 的通用检索能力,实现从单一语义匹配到多步骤推理的跃迁。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。