DeepMind推出Aletheia数学代理,实现全自主科研突破
•103 阅读•3分钟•前沿
GeminiDeepMindAletheia数学研究
•103 阅读•3分钟•前沿
关键发布
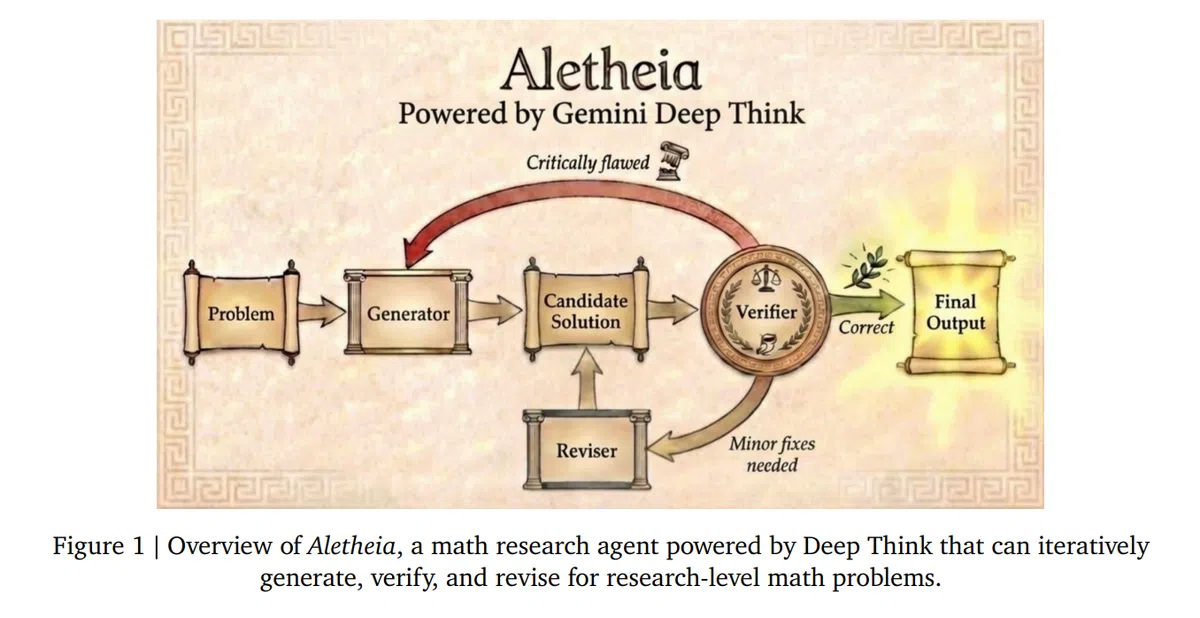
Google DeepMind今日在公开论文《Aletheia: An Autonomous Math Research Agent》中正式推出数学研究AI代理Aletheia。该系统旨在弥合国际数学奥林匹克(IMO)竞赛水平与学术前沿研究之间的差距,能够在自然语言环境下循环生成、验证并修正数学证明。
架构与技术亮点
- Agentic Loop:Aletheia 采用生成器‑验证器‑修正器三模块协同工作。生成器提出候选解答,验证器使用自然语言检查潜在错误,修正器根据反馈迭代改进直至通过。
- 底层模型:基于 Gemini Deep Think 的升级版,支持更深层次的推理与长时记忆。
- 推理时扩展:通过在推理阶段分配额外算力,实现“思考更久”,显著提升复杂证明的成功率。
- 工具使用:内置 Google Search 与网页浏览功能,主动检索最新文献,防止引用幻觉。
绩效表现
- 在 IMO‑Proof Bench Advanced 上取得 95.1% 的准确率,远超去年 65.7% 的记录。
- 同时在内部 PhD 级别基准 FutureMath Basic 中刷新了最强表现。
- 推理算力需求下降 100 倍,得益于 2026 年 1 月发布的 Deep Think 版本。
真实科研里程碑
| 项目 | 贡献方式 | 结果 |
|---|---|---|
| Fully Autonomous (Feng26) | 完全自主生成论文,计算结构常数 eigenweights | 论文已在 arXiv 上公开,质量达到可发表水平 |
| Collaborative (LeeSeo26) | 为独立集上界提供高层次路线图,帮助人类作者完成严谨证明 | 人类团队完成正式证明并提交期刊 |
| Erdős Conjectures | 针对 700 条开放问题进行搜索与求解 | 找到 63 条技术正确解答,成功解决 4 条未解题 |
自动化水平与分类标准
DeepMind 提出面向数学AI的自主度分层模型:
- Level 0:人类主导,仅用于竞赛级别(如 IMO)。
- Level 1:人机协作,产生轻度新颖性成果。
- Level 2:基本自主,能够产出可发表的研究(如 Feng26)。
Aletheia 的 Level 2 表现证明了 AI 已可在特定数学子域实现近乎独立的科研产出。
行业影响
Aletheia 的出现为学术界提供了全新工具链,尤其在需要大量文献检索与复杂推理的领域(代数几何、组合数学)具有突破性意义。与此同时,模型对算力的高效利用与工具增强策略为后续生成式AI 的可信度提升指明了方向。业界普遍预计,随着类似系统的迭代,AI 将从“解题利器”转向“科研合作者”,加速基础科学的发现速度。
“AI 能够自行提出并验证数学证明,这标志着我们进入了真正的机器科研时代。”——DeepMind 研究负责人
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。