Google发布Gemini Embedding 2 打通文本、图像、视频、音频与文档的多模态嵌入
核心技术突破
Gemini Embedding 2是Google Gemini系列的第二代嵌入模型,摆脱了以往只能处理单一模态的限制,直接将文本、图片、视频、音频和PDF文档映射到同一高维向量空间。模型默认输出3072维向量,并提供1536维、768维的精简版,满足不同算力与存储需求。
- 五大模态原生支持:
- 文本:最长8192 token
- 图片:最多6张(PNG、JPEG、WebP、HEIC/HEIF)
- 视频:最长120秒(MP4、MOV 等)
- 音频:最长80秒(MP3、WAV),无需先转写
- 文档:最多6页 PDF
- 交叉输入:开发者可在一次请求中混合多种模态,例如“图片+文字说明”或“视频片段+音频对话”,模型会在同一向量中捕获跨媒体语义关联。
Matryoshka 表示学习提升效率
传统嵌入模型在降维时会导致信息损失。Gemini Embedding 2采用Matryoshka Representation Learning (MRL),将最关键的语义信息压入向量前几维。
- 层级检索:先使用768维子向量在海量库中进行粗排,随后在全量3072维向量上完成精排,显著降低初始检索计算量。
- 存储与算力优化:在保持检索准确率的前提下,支持向量压缩至1/4,大幅降低存储成本与网络传输带宽。
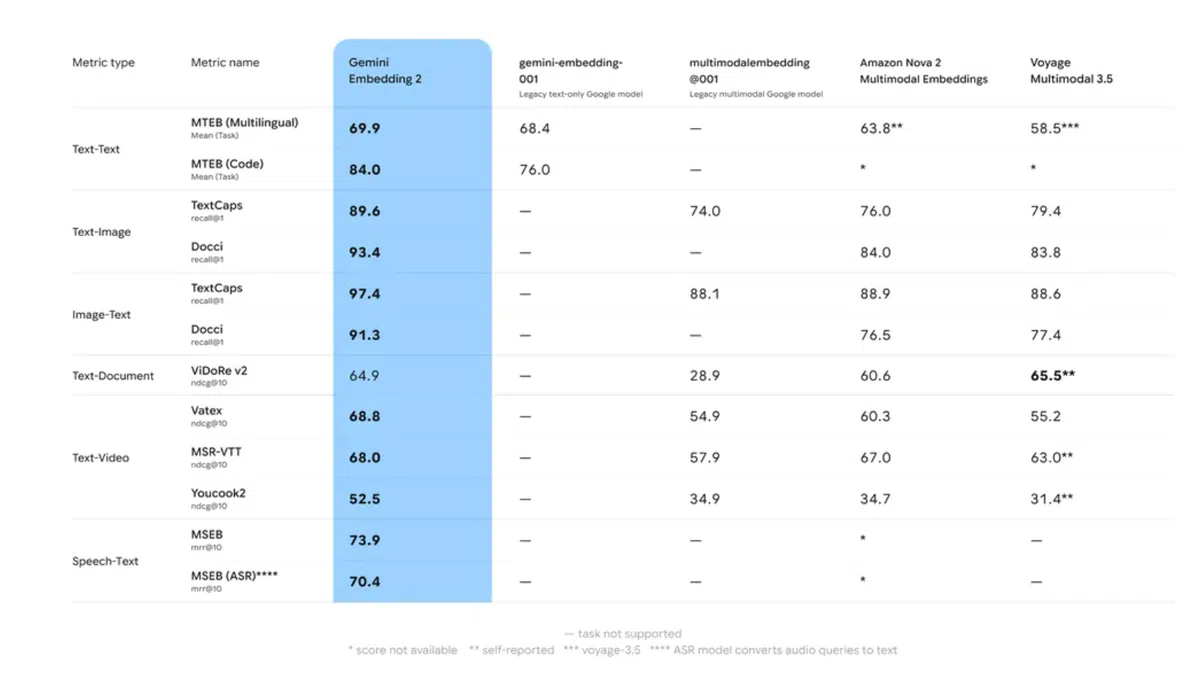
性能评估与行业意义
在Google内部的**Massive Text Embedding Benchmark (MTEB)**以及长上下文检索任务中,Gemini Embedding 2在检索准确率和域迁移鲁棒性上均超越前代模型。尤其在法律、医学等专业领域,完整的3072维向量能够捕获细粒度概念,提升RAG系统的答案质量。
"Gemini Embedding 2 的 8192‑token 窗口让我们能够一次性嵌入更长的文档块,显著缓解了 RAG 中常见的‘上下文碎片化’问题。" — Google AI 研发团队
业务落地与使用方式
模型已在 Google Cloud Vertex AI 和 Gemini API 公测,开发者可通过 task_type 参数(如 RETRIEVAL_QUERY、RETRIEVAL_DOCUMENT、CLASSIFICATION)向模型提供检索意图,进一步优化向量的数学特性。对企业而言,这意味着可以在同一检索管道中同时处理合同文本、产品图片、演示视频和语音通话记录,实现更完整的知识库覆盖。
展望
Gemini Embedding 2 的发布标志着多模态向量检索进入了“统一嵌入”时代。随着更多企业将其集成到搜索、客服、内容推荐等场景,跨媒体语义匹配的成本与门槛将进一步下降,推动 RAG 与生成式 AI 的深度融合。