DeepAgents推出自主上下文压缩功能 助力长程任务高效运行
•6 阅读•3分钟•应用
OpenAILLMDeepAgents上下文压缩
•6 阅读•3分钟•应用
背景与动机
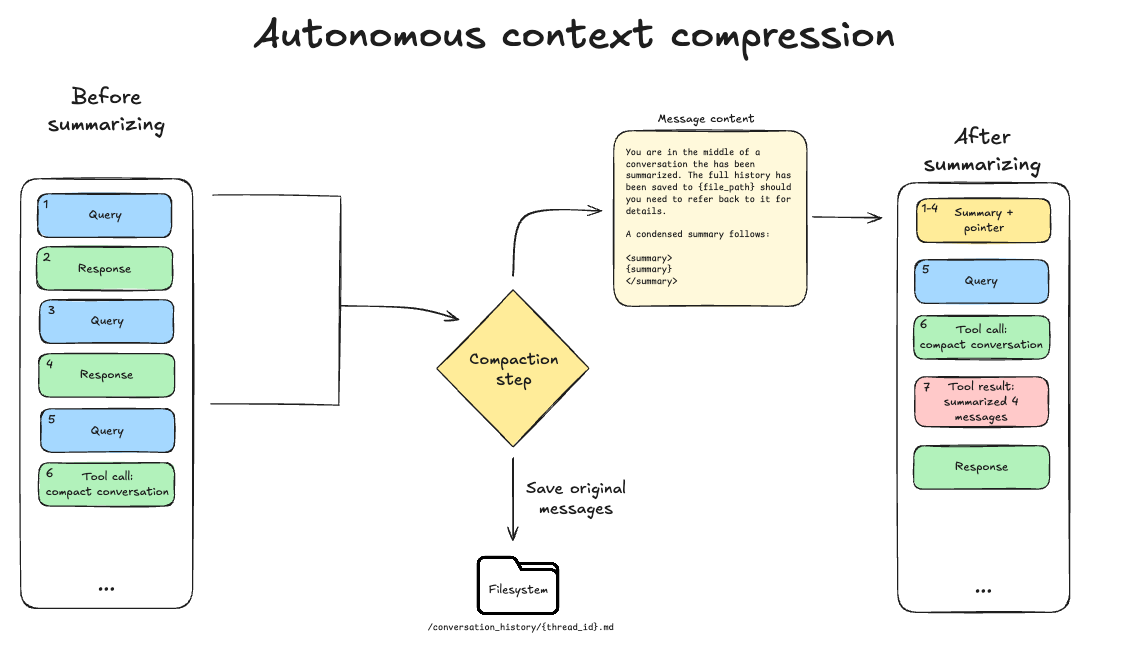
在大模型驱动的智能体中,工作记忆(上下文窗口)是有限资源。传统做法往往在达到固定 token 阈值时强制压缩,容易在关键步骤中丢失信息。DeepAgents 团队基于“bitter lesson”,提出让模型自行判断压缩时机,以实现更柔性的记忆管理。
功能概述
- 自主压缩:模型可在系统提示或自身判断下调用压缩工具,无需用户手动触发。
- 保留关键片段:压缩时保留最近 10% 的对话,确保最新指令不被削减。
- 兼容现有中间件:工具实现为
summarization中间件的扩展,使用方式与已有摘要功能一致。
何时触发压缩
| 场景 | 触发理由 |
|---|---|
| 任务边界 | 用户切换新任务或确认上一任务完成。 |
| 大量信息提取后 | 已获得关键结论或摘要,需要腾出空间继续深度分析。 |
| 即将进入大规模写作 | 准备生成长篇草稿或读取大量新文档。 |
| 复杂多步流程前 | 开始长时间的代码重构、迁移或事故响应。 |
| 上下文失效 | 新需求使先前信息失去价值,需要快速归纳。 |
使用方式
from deepagents import create_deep_agent
from deepagents.backends import StateBackend
from deepagents.middleware.summarization import create_summarization_tool_middleware
backend = StateBackend
model = "openai:gpt-5.4"
agent = create_deep_agent(
model=model,
middleware=[
create_summarization_tool_middleware(model, backend),
],
)
在 CLI 中,可直接输入 /compact 命令触发压缩。
实测与影响
DeepAgents 通过三套基准评估了该功能:
- 自定义评估套件:在需要压缩的对话中插入追问,观察模型是否主动压缩;
- Terminal‑bench‑2:未出现误触压缩,证明保守策略有效;
- 真实编码任务:在长程交互式编码中,模型在任务切换点自动压缩,显著降低了 token 消耗并提升响应速度。
整体来看,虽然压缩触发仍保持保守,但已能够在关键节点自行优化记忆,预示着未来智能体将拥有更自主的工作流管理能力。对构建长时交互或多轮推理系统的开发者而言,此功能值得在 SDK 或 CLI 中尝试。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。