NVIDIA发布Nemotron 3 Super实现120B参数开源模型多代理AI高吞吐
•11 阅读•3分钟•开源
NVIDIANemotron 3 Super多代理AI
•11 阅读•3分钟•开源
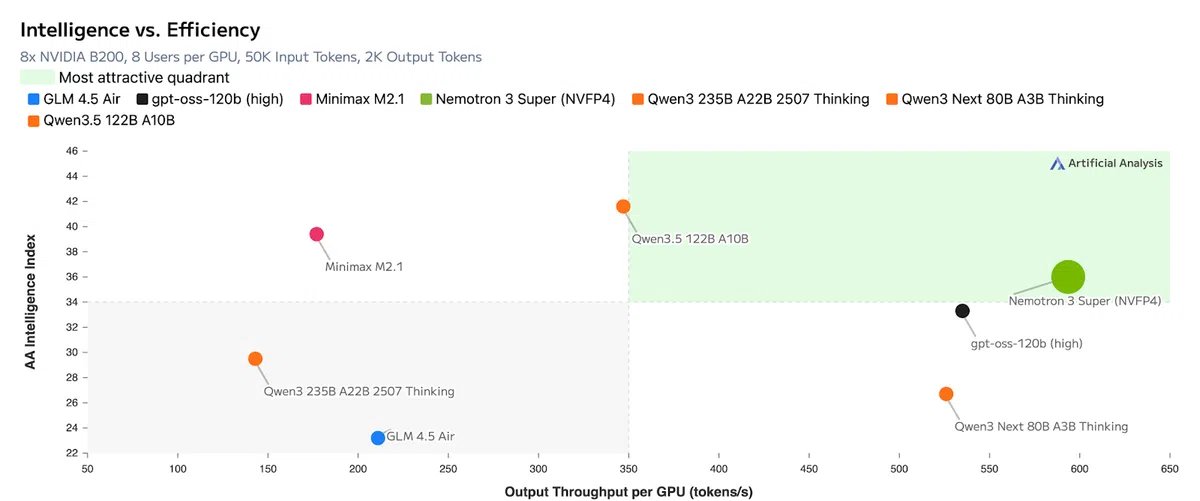
背景与意义
在大模型生态中,开源与闭源的性能鸿沟正快速收窄。NVIDIA此次发布的Nemotron 3 Super填补了中大型开源模型的空白,为需要复杂多代理协作的企业场景提供了可商用的高效推理方案。
核心技术突破
- Hybrid MoE 架构:结合内存友好的 Mamba 层与高精度 Transformer 层,仅激活部分专家即可完成生成,实现 KV 与 SSM 缓存利用率提升 4 倍。
- 多令牌预测 (MTP):一次性预测多个后续 token,推理速度提升约 3 倍。
- 1 百万上下文窗口:相较前代扩大 7 倍,支持一次性加载完整技术文档或代码库,消除多步骤“重新推理”成本。
- Latent MoE:在相同计算预算下激活四个专家,使模型在相同参数规模下达到约 35 倍模型体积的精度。
- NeMo RL Gym 集成:通过交互式强化学习环境训练,模型在动态任务(如软件工程、工具调用)中表现出双倍的智能指数。
推理预算与模式
Nemotron 3 Super 引入 Reasoning Budget 概念,提供三种可切换模式:
- Full Reasoning(默认):全力搜索,适用于复杂多步骤任务。
- Reasoning Budget:开发者可设定时延或算力上限,模型自动在约束内优化搜索路径。
- Low Effort Mode:针对简短问答或摘要场景,极致加速响应,显著降低算力消耗。
官方推荐在所有模式下使用 Temperature=1.0、Top‑P=0.95 的超参数配置,以在创造性与逻辑性之间保持最佳平衡。
实际应用案例
- 软件开发:在代码审查场景中,Nemotron 3 Super 能精准定位 bug 行,超过多数商业闭源模型的表现。
- 网络安全:通过 100+ 工具调用能力,模型在复杂安全工作流中实现自动化漏洞定位与修复建议。
- 主权 AI:印度、越南、韩国等地区的企业已基于 Nemotron 架构定制本地化模型,以满足监管与语言需求。
开源生态与可用性
模型权重、训练数据集、全套训练代码以及 RL Gym 环境全部在 Hugging Face 开源,支持 BF16、FP8 与 NVFP4 量化格式,其中 NVFP4 为在 DGX Spark 上运行的必选格式。开发者可直接通过 NVIDIA 提供的 API 接入,享受完整的推理预算控制。
展望
Nemotron 3 Super 的发布标志着开源大模型在 多代理 AI 领域的性能天花板已被显著提升。随着后续 500B 参数的 Nemotron 3 Ultra 计划在 2026 年底推出,业界将进一步观察开源模型在算力成本、可解释性及产业落地方面的竞争力。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。