NVIDIA推出VibeTensor,首个由LLM编码代理全程打造的深度学习运行时
•38 阅读•4分钟•前沿
NVIDIALLMCUDAVibeTensor
•38 阅读•4分钟•前沿
背景与意义
NVIDIA在2026年2月正式发布了 VibeTensor,这是一套完整的开源深度学习运行时系统。不同于传统由人工主导的框架开发,VibeTensor的核心代码由大语言模型(LLM)驱动的编码代理在高层人类指令下自动生成,标志着“AI 编码”进入系统级别的全新阶段。
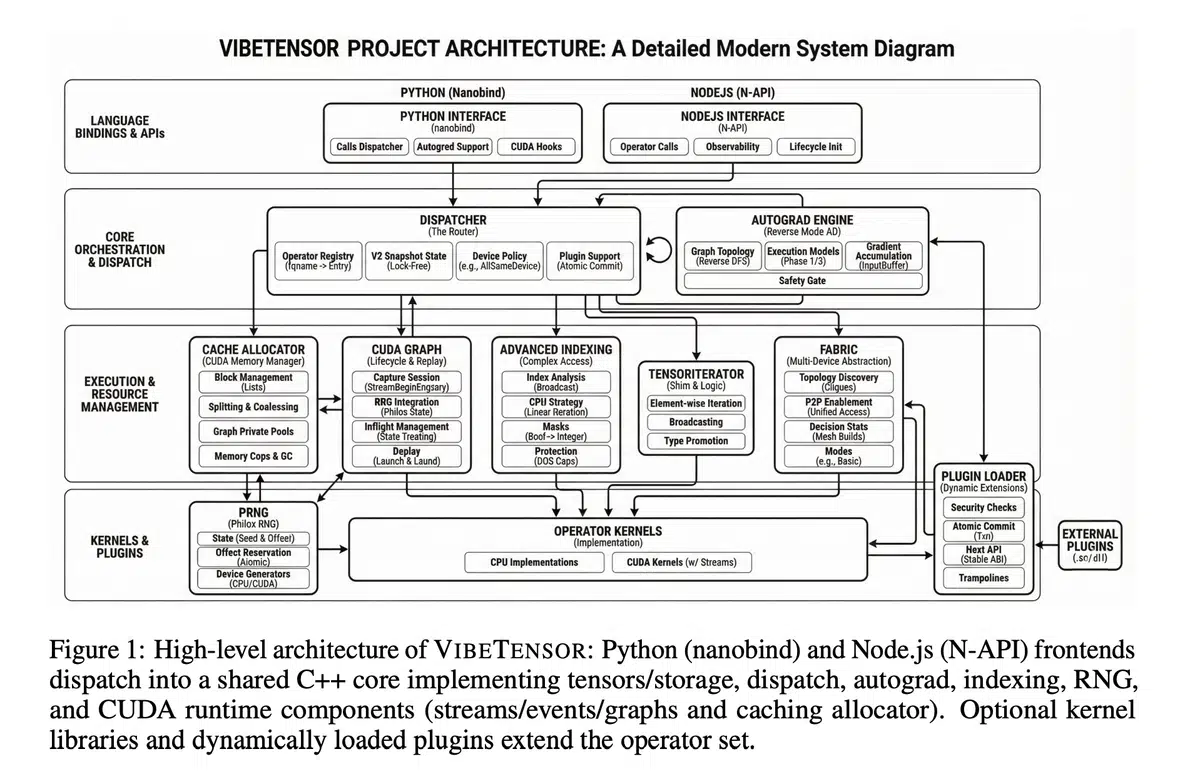
核心架构
- 跨语言前端:提供 Python(nanobind 包装)和实验性的 Node.js/TypeScript 接口,统一调用底层 C++20 实现。
- 张量与存储层:
TensorImpl与Storage采用引用计数,支持非连续视图、别名与设备元数据。 - 调度器:基于 schema‑lite 的 dispatcher 将算子映射到 CPU 与 CUDA dispatch keys,并提供 autograd 与 Python 覆盖层。
- 反向自动求导:采用 Node‑Edge 图结构,实现跨流的梯度同步与事件调度。
- CUDA 子系统:封装流、事件、CUDA Graph,并配备流序列化缓存分配器,支持诊断快照与内存上限控制。
- Fabric 多GPU 层:实验性 P2P 与统一虚拟地址支持,提供统计与事件快照,专注单进程多卡执行。
- 插件 ABI:C++ 版本化插件接口,兼容 DLPack、Safetensors,并可接入 Triton、CUTLASS 等自定义 kernel。
LLM 编码代理的研发流程
- 目标设定:研发团队在约两个月内制定功能、性能与兼容性约束。
- 代理迭代:LLM 编码代理在每轮提交代码差分后,由自动化工具链(CTest、pytest)进行编译与单元测试。
- 差分验证:通过与 PyTorch 的基准对比、长时训练回归以及分配器诊断,确保行为一致性。
- 人类审查:仅在高层次规格变更时介入人工评审,日常代码生成完全由模型完成。
“我们并未构建新的代理框架,而是把现有的大模型当作黑箱工具,让它们在严格的工具检查下自行演化代码。” — 论文作者注释
性能表现
- 微内核加速:在 Triton / CuTeDSL 编写的实验性 kernel 中,单算子比 PyTorch 基准提升约 5‑6 倍。
- 端到端训练:在 Transformer、ViT(CIFAR‑10)以及 miniGPT‑style 语言模型等完整任务上,整体训练速度仍落后 1.7‑6.2 倍,凸显系统层面优化空间。
生态与未来展望
VibeTensor 采用 Apache 2.0 许可证发布,代码已同步至 GitHub,支持 DLPack 导入导出,便于与现有框架互操作。
- 社区贡献:开放的插件 ABI 鼓励研究者提交自定义算子、调度策略以及多GPU 扩展。
- AI 编码的路线图:作者计划在后续版本中加入更细粒度的自动化测试、跨平台(Windows、ARM)支持以及更成熟的分布式训练栈。
VibeTensor 的出现为“AI 生成系统软件”提供了可验证的原型,也为业界探索 LLM 在高性能计算领域的实际落地提供了宝贵参考。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。