NVIDIA发布Nemotron‑3‑Nano 30B NVFP4版,实现高效推理
•25 阅读•3分钟•前沿
NVIDIANemotron-3-NanoNVFP4QAD
•25 阅读•3分钟•前沿
概览
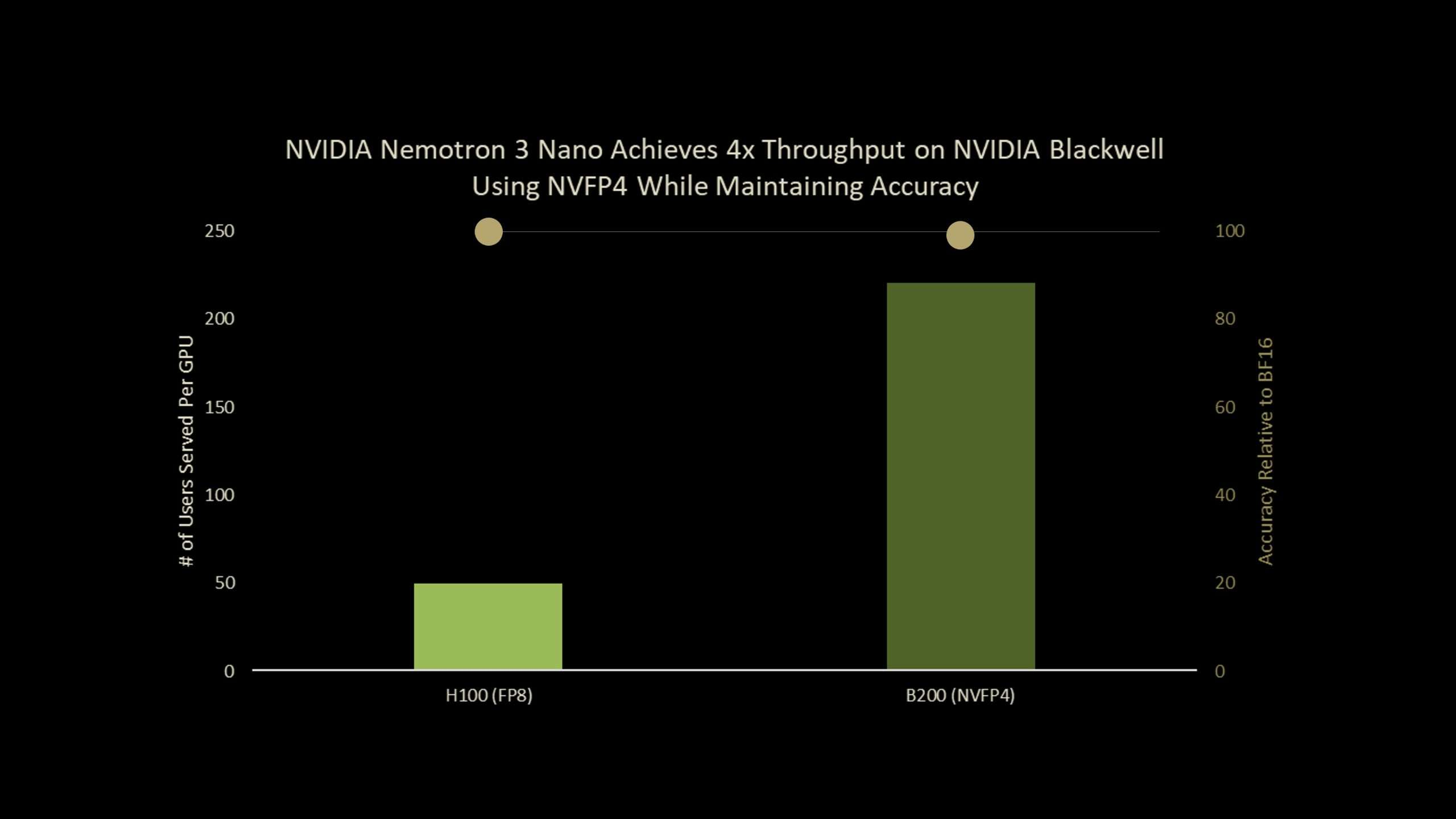
NVIDIA 今日在 HuggingFace 上公开了 Nemotron‑Nano‑3‑30B‑A3B‑NVFP4 检查点。该模型基于 30 B 参数的 Nemotron‑3‑Nano,采用 4 bit NVFP4 浮点格式并配合 量化感知蒸馏(QAD) 实现推理加速。相较于原始 BF16 基线,模型在保持 99.4% 精度的同时,可在 Blackwell B200 上实现约 4 倍吞吐提升。
模型架构与训练
- 混合 Mamba2‑Transformer MoE:52 层深度,其中 23 层为 Mamba2 与 MoE 组合,6 层为分组查询注意力(2 个组)。每个 MoE 层拥有 128 个路由专家与 1 个共享专家,单 token 激活 6 个专家,等效约 3.5 B 活跃参数。
- 预训练:在 25 T token 规模语料上使用 Warmup‑Stable‑Decay 学习率策略(峰值 1e‑3,最小 1e‑5),批次大小 3072。
- 后训练:三阶段管线——监督微调(代码、数学、科学、工具调用等)、多步骤强化学习(GRPO)以及基于生成奖励模型的 RLHF。完成后对模型进行 NVFP4 量化。
NVFP4 量化格式
NVFP4 为 NVIDIA 自研的 4 bit 浮点格式,专为最新 GPU 的训练与推理设计。主要优势:
- 与 FP8 相比,算力提升 2‑3 倍;
- 权重与激活存储压缩约 1.8 倍;
- 块大小从 32 降至 16,采用双层缩放:每块使用 E4M3‑FP8 缩放,每张量使用 FP32 缩放,兼顾局部统计适配与全局动态范围。
对大模型而言,直接后训练量化(PTQ)已能保持基本准确度;对中小模型则会出现明显精度下降,这促使 NVIDIA 研发基于训练的恢复方法——QAD。
量化感知蒸馏(QAD)
传统的量化感知训练(QAT)在多阶段后训练流水线(SFT、RL、模型合并)中难以复现,且往往缺乏原始训练数据。QAD 将目标从原始任务损失转为 KL 散度,让 NVFP4 学生模型直接模仿冻结的 BF16 教师模型输出分布。其关键特性:
- 在教师模型已完成全部微调后仍保持稳定;
- 只需输入文本即可进行蒸馏,无需标签或奖励模型;
- 相比 QAT,能够更精准地对齐高精度教师。
实验表明,在 AA‑LCR、AIME25、GPQA‑D、LiveCodeBench‑v5 与 SciCode‑TQ 等推理与编码基准上,NVFP4‑QAD 的准确率达到 BF16 的 99.4%,而 PTQ 与 QAT 均出现显著下降。
影响与展望
Nemotron‑3‑Nano‑30B‑NVFP4 的发布展示了 NVIDIA 在高效大模型推理上的前沿突破。4 bit NVFP4 结合 QAD,不仅降低显存需求,还实现了接近原始精度的推理性能,为云端大模型服务、边缘 AI 推理以及多模态工具链提供了可行路径。随着 Blackwell 系列 GPU 的算力提升,预计此类低比特量化技术将在企业级部署中快速普及。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。