智谱AI发布GLM-OCR 0.9B多模态模型实现高效文档解析与关键信息抽取
背景
文档光学字符识别(OCR)长期面临版面复杂、表格公式混杂以及结构化信息抽取困难等工程难题。传统系统在干净图片上表现尚可,但在实际业务场景中往往力不从心。为此,智谱AI与清华大学合作,推出专为 OCR 场景设计的紧凑型多模态模型 GLM-OCR。
模型架构
GLM-OCR 采用 0.4B 参数的 CogViT 视觉编码器 + 0.5B 参数的 GLM 语言解码器的组合,总体规模仅 0.9B。核心创新在于引入 多令牌预测(MTP),模型在一次解码步中生成约 5.2 个 token,较传统自回归方式提升约 50% 的吞吐量。
两阶段布局解析
系统首先使用 PP-DocLayout-V3 完成页面布局检测,将文档划分为标题、表格、公式、正文等语义块;随后在每个块上并行执行区域级识别。该设计避免了整页左至右的通用视觉语言读取,使得对复杂版面文档的处理更高效、更鲁棒。
训练流水线
GLM-OCR 的训练分为四个阶段:
- 视觉编码器的图文对与检索预训练; 2.1 多模态预训练覆盖图文、文档解析、定位与 VQA; 2.2 加入 MTP 目标;
- 针对 OCR 任务的监督微调,包括文字、公式、表格结构以及关键信息抽取(KIE);
- 基于 GRPO 的强化学习,使用编辑距离、TEDS、CDM 等任务专属奖励进行细化。
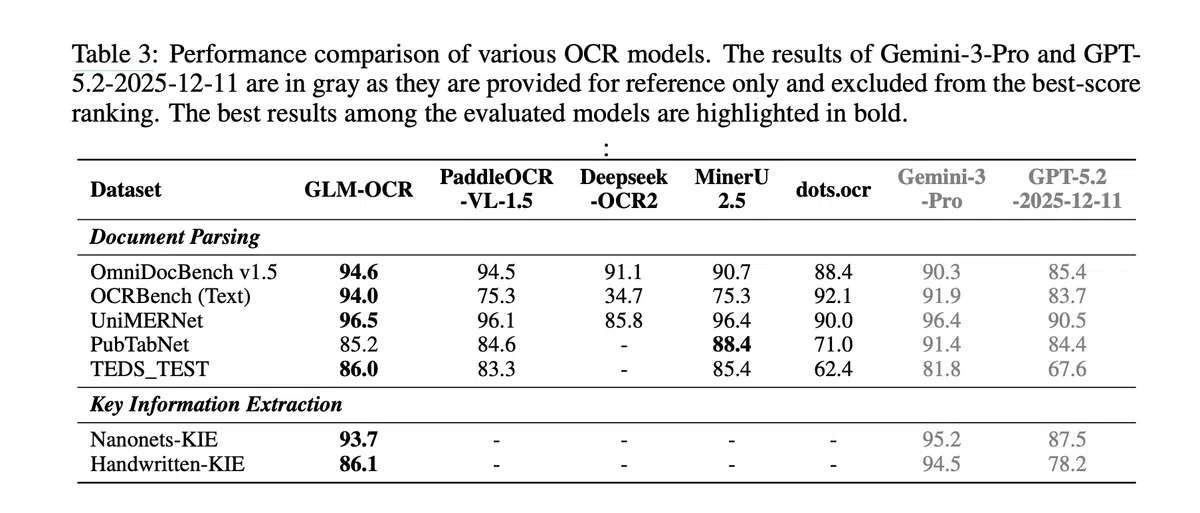
基准评测
在公开数据集上 GLM-OCR 取得了突出成绩:OmniDocBench v1.5(94.6)、OCRBench‑Text(94.0)、UniMERNet(96.5)、PubTabNet(85.2)以及 TEDS_TEST(86.0)。KIE 任务上亦达到了 Nanonets‑KIE(93.7)和 Handwritten‑KIE(86.1)的高分。需要注意的是,在 PubTabNet 上 MinerU 2.5(88.4)仍领先,且 Gemini‑3‑Pro 在参考列的 KIE 指标上更高,模型的竞争力需结合基准范围客观看待。
部署与成本
GLM-OCR 支持 vLLM、SGLang 与 Ollama,可通过 LLaMA‑Factory 进行微调。实验环境下的吞吐率为 0.67 张图片/秒、1.86 页 PDF/秒。面向企业的 MaaS API 计价为 0.2 元/百万 token,给出扫描图片与简易布局 PDF 的成本示例,表明模型已具备商业化落地的可行性。
业界意义
作为首批面向 OCR 场景专门设计的轻量多模态模型,GLM-OCR 展示了在保持高精度的前提下,如何通过架构创新和训练策略显著降低算力需求。这为边缘设备、低成本云服务以及大规模文档处理提供了新的技术选项,也为后续的多模态大模型在特定垂直领域的定制化探索指明了方向。
“我们希望通过更小的模型让高质量文档理解走进实际生产环境,而不是停留在实验室的高算力配置。”——智谱AI 研究团队