NVIDIA推出KVTC压缩技术实现LLM缓存20倍提速
•37 阅读•3分钟•前沿
NVIDIAKV缓存KVTCLlama-3.1
•37 阅读•3分钟•前沿
背景
在大规模LLM推理服务中,KV缓存往往占用数十GB显存,成为吞吐量和时延的瓶颈。传统做法要么保留缓存导致资源紧张,要么丢弃重新计算,亦或离线迁移至CPU/SSD却引入巨大的传输开销。NVIDIA针对这一痛点提出KVTC(KV Cache Transform Coding)方案,旨在通过高效压缩降低缓存存储与传输成本。
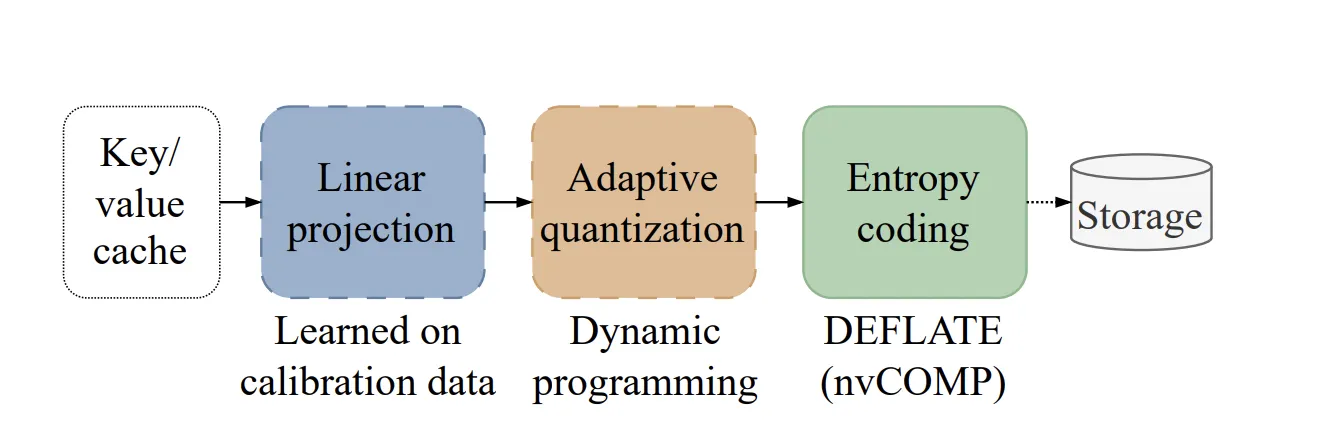
KVTC技术原理
- 特征去相关(PCA):利用主成分分析将注意力头的高维特征线性去相关,只在校准数据集上计算一次基矩阵 V,推理时直接复用。
- 自适应量化:依据主成分方差大小分配固定比特预算,采用动态规划求解最小重构误差的比特分配方案,低方差分量可直接置零,实现维度提前裁剪。
- 熵编码:使用DEFLATE算法并借助nvCOMP库在GPU上并行压缩/解压,保持毫秒级时延。
- 关键Token保护:对最旧的4个“Attention Sink”以及最近的128个“Sliding Window”Token不进行压缩,防止精度显著下降。
性能表现
| 模型 | 压缩倍率 | 精度下降 | TTFT提升 |
|---|---|---|---|
| Llama‑3.1 | ~20× (DEFLATE后) | ≤1分 | 最多8× |
| Mistral‑NeMo | ~18× | ≤1分 | 约6× |
| Qwen‑2.5 | ~22× | ≤1分 | 约7× |
校准过程仅需10分钟(12B模型在H100上),额外存储开销仅占模型参数的2.4%。KVTC不改动模型权重,兼容现有缓存淘汰策略,具备即插即用的特性。
行业意义
- 显存解放:20倍压缩让同一GPU可同时服务更多用户或容纳更大上下文。
- 时延降低:缓存传输量大幅下降,首次Token响应时间(TTFT)提升显著,提升用户交互体验。
- 生态兼容:基于通用算子实现,适配Transformer系列模型,推动LLM服务向成本敏感的生产环境落地。
“KVTC为LLM部署提供了高效、低成本的记忆管理方案,尤其在长上下文和多租户场景下价值凸显。” — NVIDIA研究团队
未来,随着模型规模继续膨胀,类似KVTC的压缩技术或将成为大模型部署的标配。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。