OAT新框架让机器人实现LLM式可伸缩动作预测,随时推理显著提速
•47 阅读•3分钟•前沿
机器人HarvardStanfordOATDiffusion Policy
•47 阅读•3分钟•前沿
背景
近年来,研究者尝试将大型语言模型(LLM)背后的自回归(AR)技术移植到机器人控制领域。若模型能预测句子下一个词,同理也应能预测机械臂的下一步动作。然而,机器人动作本质上是连续信号,难以直接映射为离散token,导致训练效率低下、推理不稳定。
OAT核心设计
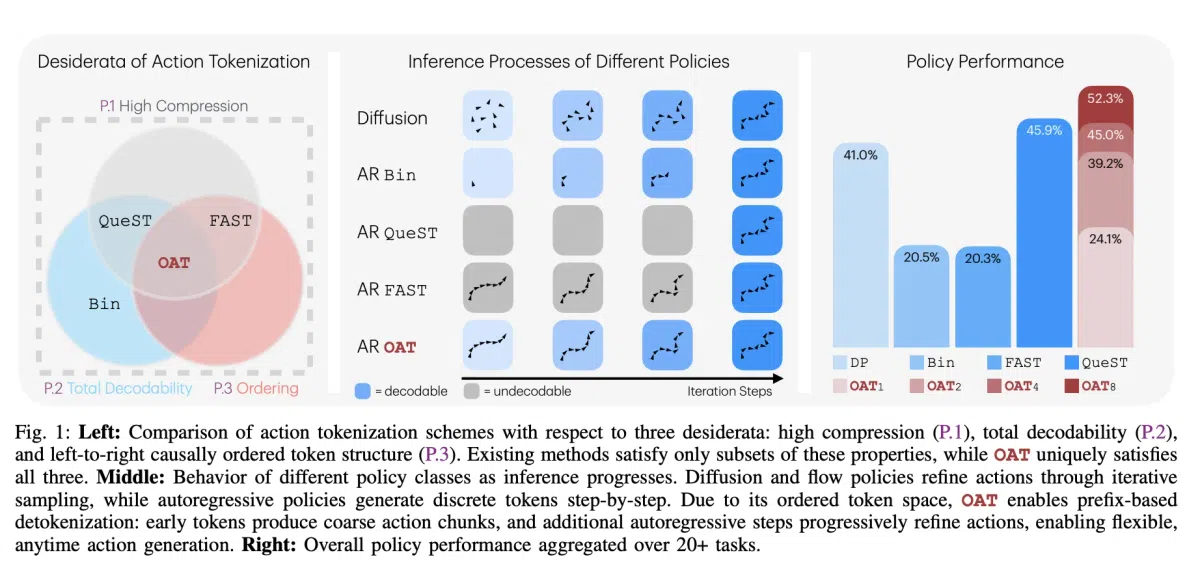
OAT(Ordered Action Tokenization)提出三大黄金法则:
- 高压缩(P.1):通过嵌套Dropout和寄存器(token register)机制,将长序列压缩至仅8个token。
- 全解码(P.2):解码器被设计为全函数(total function),任意token序列都能映射到合法的动作片段,避免运行时卡死。
- 因果顺序(P.3):token 按重要性从左至右排列,前置token 捕获全局粗略运动,后置token 负责细粒度修正。
实现上,OAT 使用Transformer编码器对动作块进行嵌入,并引入嵌套Dropout让模型在训练过程中自动学习“先重要后细节”的层次结构。
实验结果
在LIBERO、RoboMimic、MetaWorld、RoboCasa四大仿真平台共20余项任务中,OAT 的成功率均领先于业界基准 Diffusion Policy(DP)和传统离散化方案。关键数据如下:
- LIBERO:OAT 56.3% vs DP 36.6%(token 数 8 vs 224)
- RoboMimic:OAT 73.1% vs DP 67.1%(token 数 8 vs 224)
- MetaWorld:OAT 24.4% vs DP 19.3%(token 数 8 vs 128)
- RoboCasa:OAT 54.6% vs DP 54.0%(token 数 8 vs 384)
“随时推理”优势
由于 token 按重要性排序,用户可在推理过程中提前截断:
- 粗略动作:仅解码前1‑2个 token,即可得到大致运动方向,适用于低时延场景。
- 细致动作:完整解码全部8个 token,获得高精度轨迹,用于复杂装配或精细抓取。
这种前缀式解码在计算成本与执行精度之间提供了灵活的权衡,是传统固定长度 tokenizer 所不具备的特性。
影响与展望
OAT 为将 LLM 的自回归规模化优势迁移到机器人控制奠定了可行路径。它不仅解决了动作离散化的技术瓶颈,还通过“随时推理”打开了实时机器人交互的新可能。未来工作可聚焦于:
- 将 OAT 与真实硬件闭环实验相结合,验证在实际工业场景的鲁棒性;
- 探索更大规模的 transformer 以及多模态感知输入,进一步提升策略的通用性。
OAT 的发布标志着机器人学习进入了类似 GPT‑3 的快速迭代时代,期待后续研究在真实世界中实现更高效、更可靠的动作生成。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。