斯坦福推出OpenJarvis 本地化个人AI代理框架实现全栈开源
•0 阅读•4分钟•开源
LLMAgentStanfordOpenJarvis本地推理
•0 阅读•4分钟•开源
项目概览
近日,斯坦福大学Scaling Intelligence实验室正式开源OpenJarvis。该框架旨在提供一个完整的软件栈,使个人AI代理能够在用户设备上全链路运行,摆脱对云端API的依赖,实现低延迟、低成本且数据本地化的交互体验。OpenJarvis不仅包含模型执行层,还提供了工具调用、记忆管理和自学习机制,覆盖了从模型选择到任务完成的全部环节。
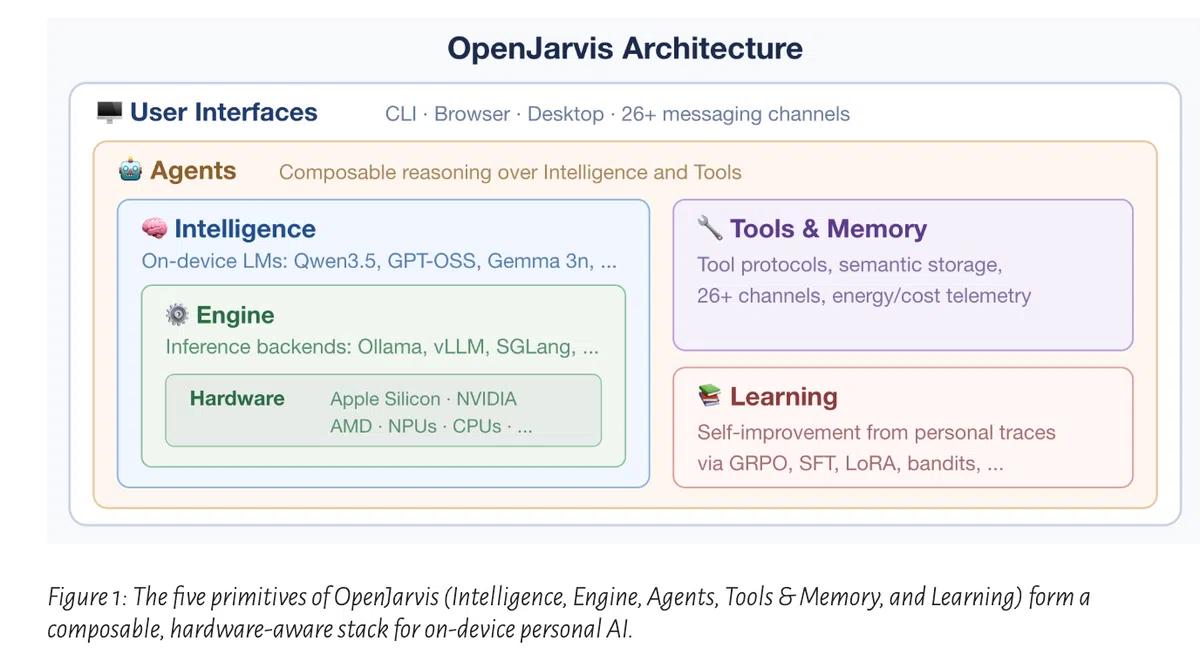
五大原语架构
- Intelligence(模型层):统一管理本地模型目录,自动匹配参数规模、硬件兼容性和内存需求,支持Ollama、vLLM、SGLang、llama.cpp等多种模型后端。
- Engine(推理运行时):抽象硬件感知的执行接口,提供
jarvis init检测设备并推荐最佳模型/引擎组合,jarvis doctor帮助维护运行状态。 - Agents(行为层):将模型能力转化为结构化行动,支持可组合的角色,如任务拆解的Orchestrator和轻量执行的Operative,完整管理系统提示、工具、上下文及重试逻辑。
- Tools & Memory(工具与记忆层):实现标准化的工具协议(MCP)和模型上下文协议(Google A2A),并提供本地语义索引,支持文件、笔记、网页、计算器等多模态工具的调用。
- Learning(闭环学习层):利用本地交互痕迹自动生成训练数据,支持SFT、DPO、GRPO等微调方法,实现模型权重、提示、代理逻辑和推理引擎的全链路优化。
效率与评价
OpenJarvis将能耗、FLOPs、延迟和成本视为第一类约束。通过NVML、AMD GPU监控和Apple Silicon powermetrics实现硬件无关的能耗采样(50 ms间隔),并提供jarvis bench统一基准,量化每次查询的时延、吞吐和能耗。实验数据显示,基于最新本地模型和加速器,单轮对话和推理查询的本地执行率已达88.7%,相较2023年提升5.3倍,验证了“Intelligence‑Per‑Watt”研究的可行性。
开发者体验与部署选项
OpenJarvis提供多种入口:
- 浏览器/桌面应用:一键脚本
./scripts/quickstart.sh即可完成依赖安装、模型启动、后端服务和前端 UI 的全流程。 - Python SDK:
Jarvis()对象封装ask()、ask_full()等方法,便于在脚本或服务中直接调用。 - CLI:
jarvis ask、jarvis serve、jarvis memory index等命令覆盖从交互到记忆管理的全部功能。 - FastAPI 兼容层:
jarvis serve可生成兼容OpenAI API 的 SSE 流式接口,帮助开发者平滑迁移现有应用。所有核心功能均可在完全离线的环境下运行,云端服务仅作可选插件。
业界意义
OpenJarvis的发布标志着本地化AI从概念验证迈向生产化。它为研究者提供了统一的基准平台,帮助评估不同模型、硬件与算法的能效 Trade‑off;同时为企业和个人开发者提供了可直接部署的技术栈,降低了对昂贵云算力的依赖。随着消费级硬件算力的持续提升,类似OpenJarvis的本地-first 生态有望加速生成式AI在隐私安全、边缘计算和离线场景的落地。
“本地化不再是性能的牺牲,而是可控、低成本的全新范式。”——斯坦福Scaling Intelligence实验室负责人
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。