Google推出PaperBanana 多代理框架实现论文图表自动化生成
•32 阅读•3分钟•前沿
Google多代理系统北京大学PaperBanana学术可视化
•32 阅读•3分钟•前沿
背景与动机
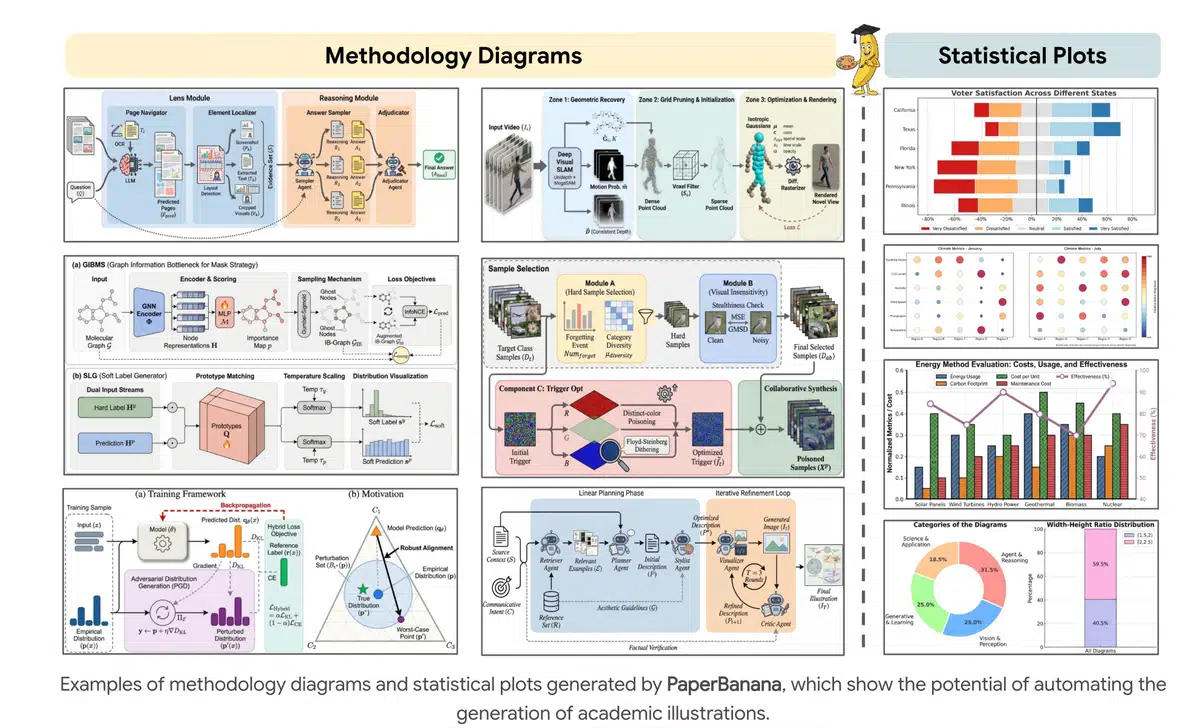
在科研写作中,生成符合期刊规范的示意图和统计图往往需要手工绘制,耗时且易出错。随着大模型在文本理解和代码生成方面的突破,Google 与北京大学团队提出了 PaperBanana,通过五个专职智能体协同工作,实现从原始方法描述到出版级图形的全链路自动化。
系统架构
PaperBanana 采用两阶段生成流程:
-
线性规划阶段
- Retriever Agent:从图形库中检索最相似的 10 条参考样例,为后续设计提供风格基准。
- Planner Agent:将技术方法文本拆解为结构化的图形描述。
- Stylist Agent:依据 "NeurIPS Look" 风格指南,生成配色、布局等视觉指令。
-
迭代细化阶段
- Visualizer Agent:根据描述生成视觉输出。对示意图使用图像模型 Nano‑Banana‑Pro;对统计图则输出可执行的 Matplotlib 代码。
- Critic Agent:对生成结果进行事实核对和视觉检查,提出错误修正建议并触发最多三轮迭代。
该框架的核心理念是“参考驱动 + 多智能体协作”,避免单一 Prompt 的不确定性。
基准评测(PaperBananaBench)
团队构建了 PaperBananaBench,收录 292 条来自 NeurIPS 2025 的真实论文案例,使用 VLM‑as‑Judge 进行客观评分。主要指标提升如下:
- 整体得分 +17.0%
- 简洁性 +37.2%
- 可读性 +12.9%
- 美观度 +6.6%
- 忠实度 +2.8%
在 “Agent & Reasoning” 类图示中,系统获得 69.9% 的最高分,显示出对复杂交互式示意图的强大适配能力。
统计图生成的双模式策略
PaperBanana 区别于传统图像生成模型的关键在于 代码生成模式:
- 图像生成 (IMG):适用于视觉美感要求高的示意图,但可能出现数值幻觉。
- 代码生成 (Coding):直接输出 Matplotlib 脚本,确保 100% 数据忠实,尤其在密集或多系列数据场景下表现更佳。
应用前景与行业影响
该框架不仅能显著降低科研团队的图形制作成本,还为期刊编辑、学术搜索引擎提供结构化的图形元数据,促进跨文献可视化分析。未来可扩展至医学影像报告、专利图示等高精度可视化需求。
结语
PaperBanana 展示了多代理协作在专业化生成任务中的潜力,标志着 AI 从通用文本生成向高质量学术可视化迈出关键一步。随着更多领域加入参考驱动的多智能体体系,科研工作流的自动化水平有望进一步提升。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。