百度发布Qwen3-Coder-Next 开源大模型 实现高效编码代理
•28 阅读•4分钟•开源
百度MoEQwen3-Coder-NextSWE-Bench
•28 阅读•4分钟•开源
模型概述
近日,百度旗下的通义千问团队发布了全新开源大模型 Qwen3‑Coder‑Next。该模型基于 Qwen3‑Next‑80B‑A3B 主干,采用稀疏 Mixture‑of‑Experts(MoE)架构,整体参数量 80 B,但每个 token 只激活约 3 B 参数,实现了大模型的容量与低推理成本的平衡,专为编码代理和本地开发场景设计。
技术创新
- Hybrid Attention + Sparse MoE:模型在 48 层网络中交替使用 Gated DeltaNet、Gated Attention 与 MoE 模块;MoE 共有 512 位专家,单 token 采用 10 + 1 个专家激活,提供细粒度专家化能力。
- 256K 长上下文:支持单次会话超过 25 万 token,能够一次性读取完整代码库、日志或对话历史。
- 非思考模式(non‑thinking):模型输出仅为工具调用与直接代码片段,不产生额外的思考文本,便于与 IDE、CLI 代理无缝对接。
代理训练与基准表现
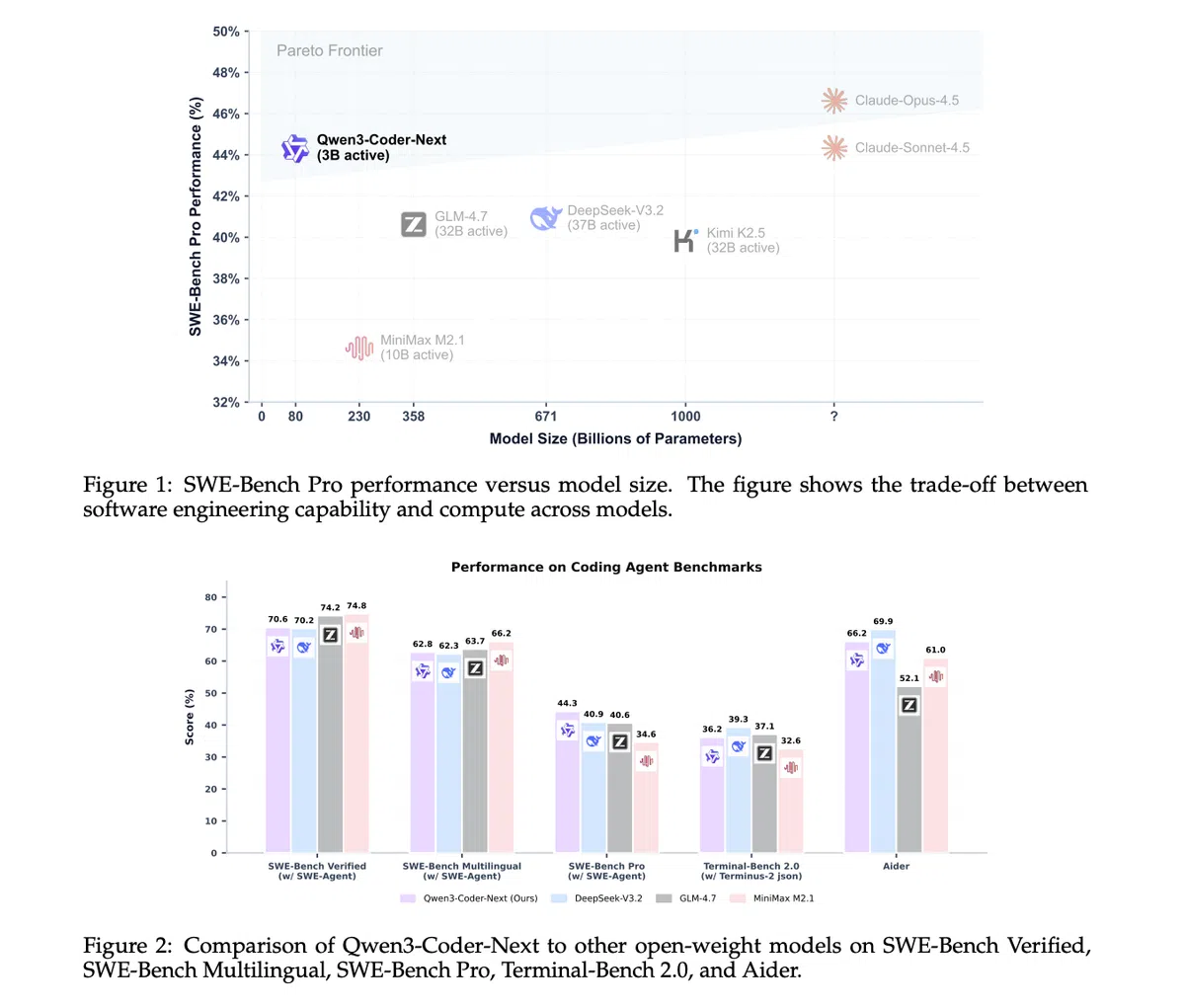
团队采用“可执行任务+强化学习”大规模训练方案,约 80 万可验证任务覆盖代码生成、工具序列、运行测试与错误恢复。基准结果显示:
| 基准 | Qwen3‑Coder‑Next | 同类大型模型 |
|---|---|---|
| SWE‑Bench Verified | 70.6 | DeepSeek‑V3.2 70.2 / GLM‑4.7 74.2 |
| SWE‑Bench Multilingual | 62.8 | DeepSeek‑V3.2 62.3 / GLM‑4.7 63.7 |
| SWE‑Bench Pro | 44.3 | DeepSeek‑V3.2 40.9 / GLM‑4.7 40.6 |
| Terminal‑Bench 2.0 | 36.2 | 与更大参数模型持平 |
| Aider | 66.2 | 接近同类最佳水平 |
这些数据表明,在编码代理和长程推理场景下,Qwen3‑Coder‑Next 的表现可媲美甚至超越参数量高出 10‑20 倍的模型。
部署与生态
- 服务器部署:推荐使用 SGLang(≥0.5.8)或 vLLM(≥0.15.0),通过
--tool-call-parser qwen3_coder启用工具调用解析,提供兼容 OpenAI/v1接口。 - 本地部署:Unsloth 提供 GGUF 量化模型,4‑bit 版约需 46 GB 显存,8‑bit 版约 85 GB,支持 llama.cpp 与 llama‑server 完整工作流,默认上下文 32 K,最大可达 262 K。
- 生态集成:已适配 Qwen‑Code、Claude‑Code、Cline 等主流编码代理前端,开发者可直接替换模型名称完成迁移。
关键要点
- 稀疏 MoE 设计:80 B 总参数、3 B 活动计算,实现高容量与低成本的最优组合。
- 长上下文与混合注意力:256 K token 支持,使大型代码库一次性读取成为可能。
- 代理式训练:大规模可执行任务与 RL 让模型具备工具调用、错误恢复等真实开发需求。
- 开源与易部署:Apache‑2.0 许可证、完整量化模型与多平台部署指南,降低企业与个人私有化部署门槛。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。