蚂蚁集团Robbyant开源LingBot-World 实时交互式世界模型提升具身AI能力
•22 阅读•3分钟•开源
Ant GroupRobbyantLingBot-World具身智能
•22 阅读•3分钟•开源
关键亮点
- 实时交互:模型接受键盘(W/A/S/D)和摄像机动作输入,能够在毫秒级响应下生成连续视频。
- 长时程生成:在推理阶段可自回归滚动至约10分钟,保持场景结构和几何一致性。
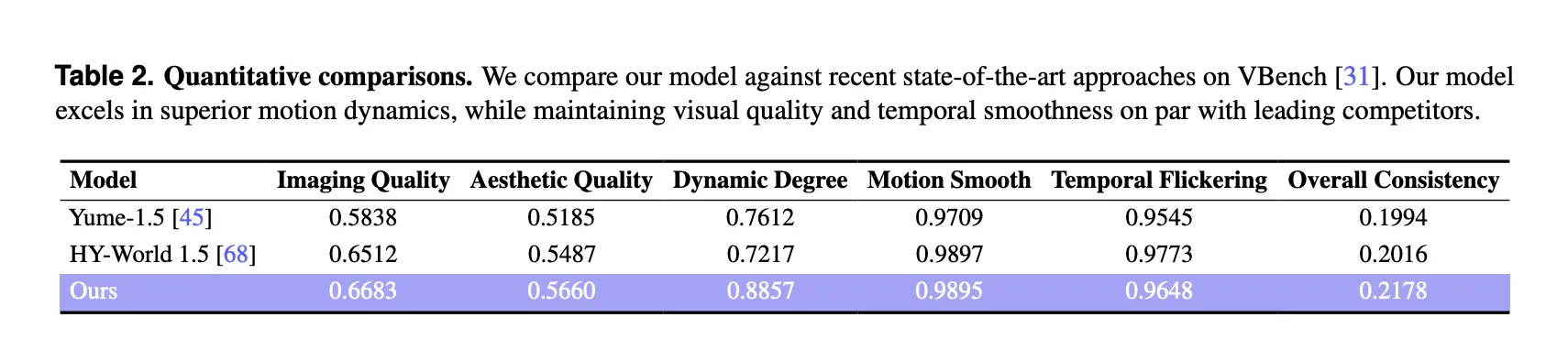
- 高视觉保真:支持720p分辨率,动态度指标在公开基准VBench上领先同类模型近0.13。
- 完全开源:代码、模型权重及数据处理管线全部公开,社区可直接复现并二次开发。
技术架构
LingBot-World 基于 Wan2.2(14B 参数的图像‑视频扩散 Transformer)构建,进一步演化为 Mixture‑of‑Experts DiT,拥有两套 14B 参数的专家网络,仅激活一套进行去噪,从而在保持 28B 总容量的同时,推理成本与单专家模型相当。
动作注入 采用 Plücker 嵌入编码摄像机旋转,键盘动作转化为多热向量,随后通过自适应层归一化模块调制 Transformer 隐层,实现动作对生成过程的直接调控。主干网络保持冻结,只微调动作适配层,确保视觉质量不受交互数据规模限制。
实时加速方案
原始模型依赖全局时序注意力和多步扩散,成本高昂。为实时使用,团队推出 LingBot-World‑Fast:
- 块因果注意力:在每个时间块内部双向注意,块间采用因果方式,支持 KV‑Cache,实现帧流式输出。
- 扩散强制蒸馏:学生模型在高噪声阶段学习,并在 0 步骤直接生成清晰帧,配合对抗判别头提升生成质量。
- 性能:在单 GPU(480p)下可达 16 FPS,端到端交互延迟低于 1 秒。
评估与对标
在 VBench 上对 100 条 ≥30 秒视频进行评测,LingBot-World 在 Imaging Quality、Aesthetic Quality、Dynamic Degree 三项均领先 Yume‑1.5 与 HY‑World‑1.5,动态度提升 0.124。与交互系统 Matrix‑Game‑2.0、Mirage‑2、Genie‑3 相比,LingBot‑World 在覆盖领域、生成时长、分辨率及实时性上保持唯一优势。
应用前景
- 具身AI训练平台:可将生成的视频流直接喂给视觉‑语言‑动作模型(如 Qwen3‑VL‑2B)进行策略学习。
- 自动驾驶仿真:通过真实世界车辆轨迹与动作标签,构建可交互的道路场景,降低真实路测成本。
- 游戏与虚拟制作:开发者可通过自然语言指令快速搭建并实时操控场景,实现“文本即世界”。
- 3D 重建:几何一致的视频序列提供稳健的点云输入,支持室内外结构的自动重建。
结语:LingBot-World 将文本‑视频生成的被动特性彻底转变为可控、长时程的交互式仿真,为具身智能的闭环训练提供了前所未有的底层设施。其完全开源的姿态也为学术界和产业链的协同创新打开了新窗口。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。