DeepSeek AI发布DeepSeek-OCR 2,因果视觉流编码提升布局感知文档理解
•25 阅读•4分钟•开源
DeepSeek AIDeepSeek-OCR 2Qwen2-0.5B文档理解
•25 阅读•4分钟•开源
背景概览
DeepSeek AI最新开源的DeepSeek-OCR 2是一款面向复杂版面文档的光学字符识别与结构理解系统。相较于传统的从左上到右下的栅格顺序,DeepSeek-OCR 2通过因果视觉流编码,使模型更贴近人类的阅读顺序,从而在多列、混排、公式与表格密集的页面上表现更佳。
核心技术
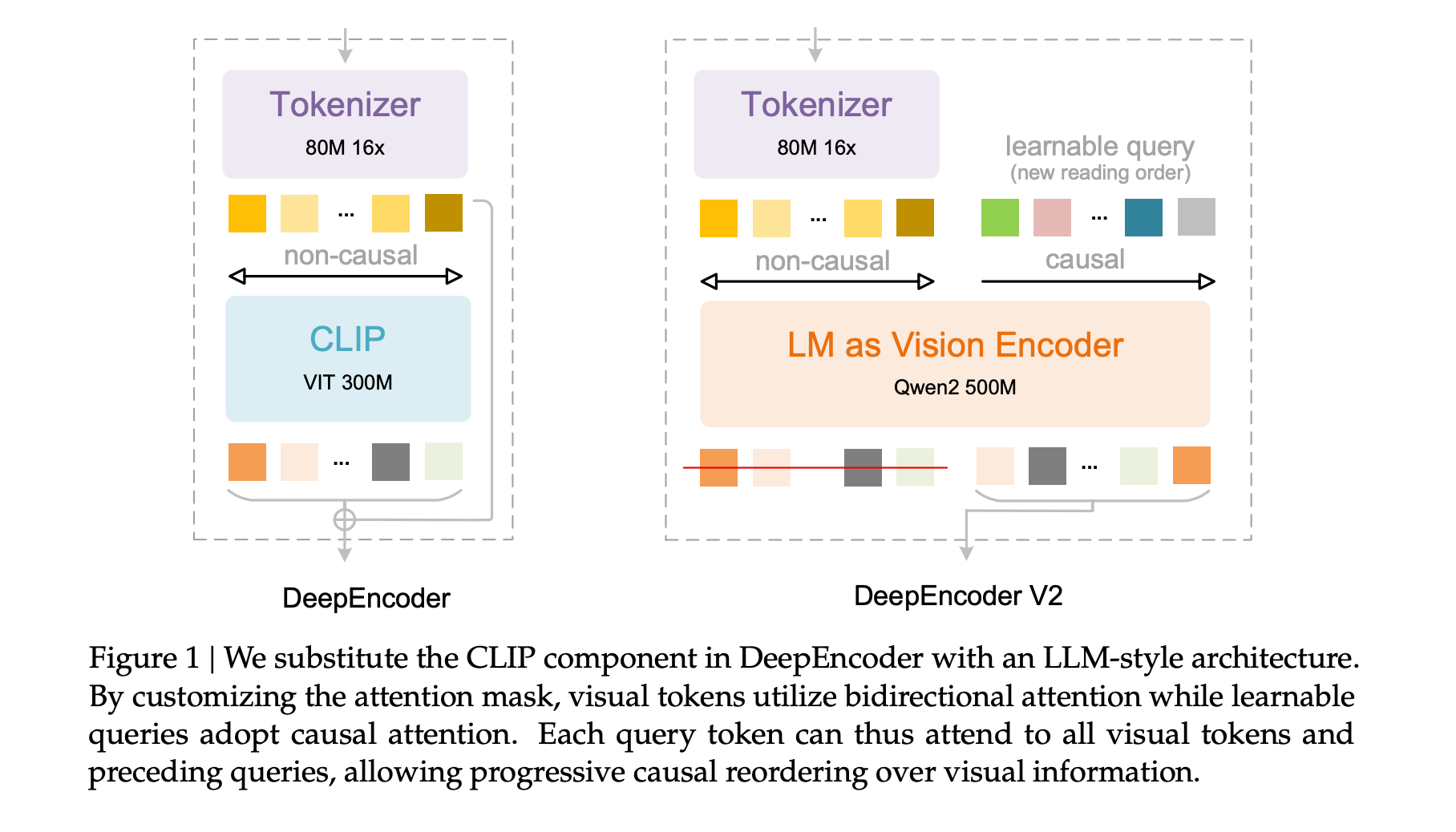
- DeepEncoder‑V2:基于 Qwen2‑0.5B 架构的视觉编码器,将视觉令牌视作前缀,随后追加等量的因果流令牌(causal flow tokens)。视觉令牌使用双向注意力,因果流令牌仅能看到前面的因果流令牌,实现从二维网格到一维阅读序列的映射。
- 视觉分词器:沿用原 DeepSeek-OCR 的 80M 参数 SAM‑base 主干,加两层卷积,将图像下采样 16 倍,得到 896 维嵌入。全局视图(1024×1024)产出 256 令牌,最多 6 张局部裁剪(768×768)各增 144 令牌,单页令牌数控制在 256‑1120 之间,低于原模型的 1156 预算。
- 解码器:DeepSeek‑3B‑A500M 为 3B 参数的 MoE 语言模型,实际激活约 500M 参数,负责在已排序的视觉令牌上进行文本生成。
训练流程
训练分为三阶段:
- 编码器预训练:使用小型解码器,目标为语言模型预训练,分辨率 768×768 与 1024×1024 多尺度采样,使用 AdamW,学习率 1e‑4→1e‑6,约 40k 步,耗时 160 张 A100 GPU。
- 查询增强联合训练:冻结分词器,编码器‑解码器共同训练,采用 4‑stage pipeline 并行,全局 batch size 为 1280,迭代 15k,学习率 5e‑5→1e‑6。
- 解码器微调:冻结全部编码器参数,仅微调解码器,学习率 1e‑6→5e‑8,迭代 20k,使训练吞吐率翻倍。
数据比例聚焦 OCR,OCR 数据占 80%,文本‑公式‑表格采样比为 3:1:1,确保模型在结构密集场景下拥有足够曝光。
基准表现
在 OmniDocBench‑v1.5(1355 页、9 类文档)上,DeepSeek‑OCR 2 获得整体得分 91.09,较原版 87.36 提升 3.73 分,且令牌上限更小。阅读顺序编辑距离从 0.085 降至 0.057,文本编辑距离从 0.073 降至 0.048,公式与表格的误差同样下降。元素级编辑距离为 0.100,优于原模型的 0.129 以及 Gemini‑3 Pro 的 0.115。
行业意义
DeepSeek‑OCR 2 的因果视觉流设计为文档理解提供了新的思路:将视觉编码与阅读顺序融合,使多列、混排文档的解析更符合人类认知。作为完全开源的项目,社区可以直接复用其视觉分词器与训练管线,进一步推动中文文档 OCR 与结构化处理的生态发展。
“从二维到一维的阅读流映射,是布局感知的关键突破。”——DeepSeek AI 研究团队
获取方式
项目代码、模型权重及完整论文已同步至 GitHub:https://github.com/deepseek-ai/DeepSeek-OCR-2,欢迎开发者下载实验。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。