DeepAgents SDK推出多层上下文压缩,提升长任务执行效率
•21 阅读•3分钟•开源
LangChainDeepAgents上下文压缩
•21 阅读•3分钟•开源
背景
在可寻址任务长度持续扩展的时代,LLM 的上下文窗口成为制约代理性能的瓶颈。DeepAgents SDK 作为 LangChain 开源的全栈代理框架,旨在为开发者提供计划、子代理生成以及文件系统交互等能力,同时通过一套上下文压缩机制,防止“上下文腐化”。
核心压缩技术
1. 大工具结果离线
- 当工具调用(如读取大文件或外部 API)返回的内容超过 20,000 tokens 时,SDK 自动将完整响应写入文件系统。
- 会话中仅保留文件路径引用及前 10 行预览,后续需要时可重新读取或搜索。
2. 大工具输入离线
- 文件写入、编辑等操作会在对话历史中留下完整的文件内容。
- 当会话占用的上下文比例超过模型窗口的 85%,SDK 将旧的工具调用截断,替换为磁盘文件指针,从而显著压缩活跃上下文。
3. 摘要压缩
- 若离线已无法提供足够空间,系统启动 摘要压缩。
- 在上下文摘要:LLM 生成结构化摘要,涵盖会话意图、已生成的制品以及后续步骤,替代完整对话。
- 文件系统持久化:原始对话全文被写入文件系统,确保关键细节可通过搜索检索。
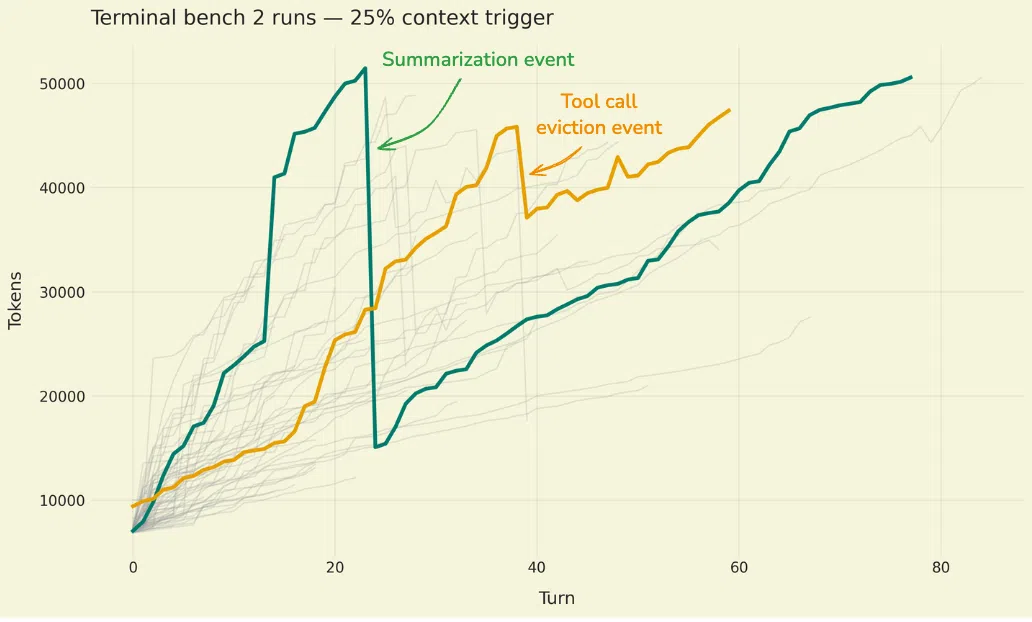
实验与评估
DeepAgents 在 terminal-bench-2 基准上进行评估,使用 Claude Sonnet 4.5 进行对比。实验显示:
- 在第 20 步触发摘要时,整体 token 使用骤降约 30%(绿色线)。
- 第 40 步大文件写入被离线后,token 使用下降约 10%(橙色线)。
- 将压缩阈值从默认 85% 调整至 25% 可产生更多压缩事件,帮助研发者快速定位不同压缩策略对性能的影响。
目标导向的评估
SDK 附带一套 针对性评估,专注验证单项压缩机制:
- 摘要保留意图:在任务中途强制触发摘要,检查代理是否仍能沿着原始目标前进。
- 信息可恢复性:在对话早期植入“针孔”信息,摘要后要求代理检索该信息,以验证文件系统搜索的有效性。
这些小型测试充当集成测试,帮助开发者在完整基准运行前快速发现压缩相关的缺陷。
实践指南
- 基准跑通:先在真实任务上跑通,记录基线 token 使用与成功率。
- 激进压缩:将压缩阈值调低至 10‑20%,制造更多压缩事件,以放大各特性的信号。
- 检验恢复:加入针孔检索测试,确保关键信息在摘要后仍可通过文件系统检索到。
- 监控目标漂移:关注摘要后代理是否出现意图偏移,如频繁询问或提前宣告任务完成。
通过上述步骤,开发者可以系统化地评估并优化自己的上下文管理策略,使长时序任务在有限的 LLM 记忆空间内保持高效运行。
全部特性均已开源,欢迎在 GitHub 上获取最新代码并提交使用反馈。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。