Liquid AI发布1.2B思考模型,实现千兆参数手机离线推理
•40 阅读•3分钟•开源
大语言模型开源模型工具使用边缘推理
•40 阅读•3分钟•开源
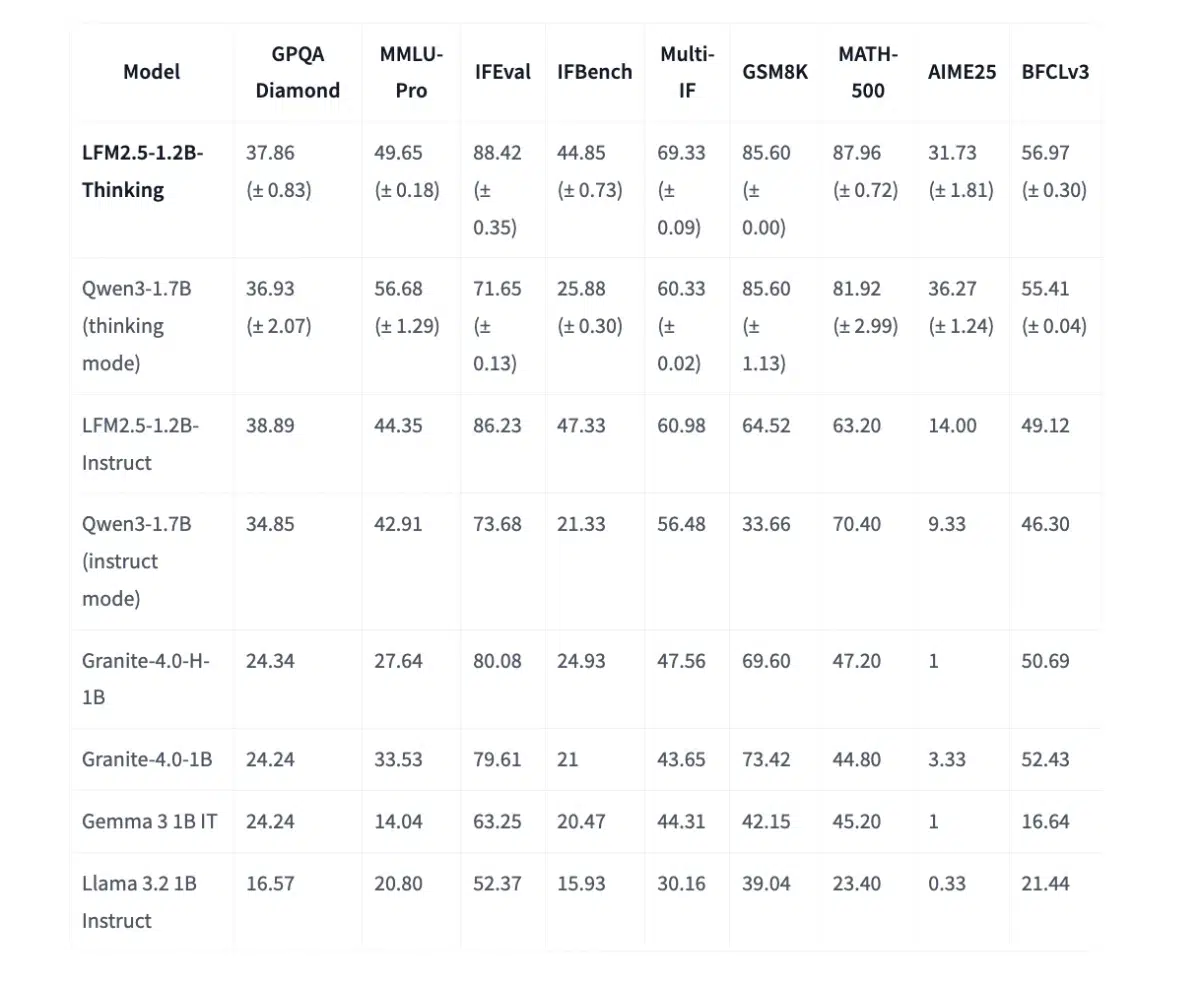
Liquid AI 今日宣布正式发布 LFM2.5-1.2B‑Thinking,一款参数约 1.2 B、专注推理的轻量化大语言模型。该模型可在现代智能手机上完整运行,模型体积约 900 MB,内存占用低于 1 GB,实现了过去只能依赖数据中心的结构化推理、工具调用和数学计算在端侧离线执行。
模型概览
- 参数量:1.17 B(归类为 1.2 B 级)
- 层数:16 层,包含 10 个双门 LIV 卷积块和 6 个 GQA 块
- 词表:65 536,支持 8 种语言(英、阿、中文、法、德、日、韩、西)
- 上下文长度:32 768 Token
- 特色:推理优先的 “Thinking” 变体,输出内部思考链路(thinking trace),便于规划工具调用和多步骤指令。
推理性能与硬件足迹
在 AMD 桌面 CPU 上解码速率约 239 Token/s;在移动 NPU(Qualcomm)上约 82 Token/s。模型文件提供 GGUF、ONNX、MLX 等多种格式,兼容 llama.cpp、FastFlowLM、vLLM 等主流推理框架,真正做到“一键上手、即插即用”。
训练技术与循环抑制
为防止常见的 “doom‑loop” 循环,Liquid AI 采用多阶段训练流水线:
- 中期训练加入推理链路,引导模型先思考再回答;
- 合成思考链路的监督微调提升链路质量;
- 偏好对齐(Preference Alignment)使用 5 条采样候选 + 1 条贪婪候选,由 LLM 判别优劣;
- RLVR 阶段加入 n‑gram 重复惩罚,将循环率从 15.74% 降至 0.36%。
实际应用场景
- Agent 工作流:作为规划大脑,为工具链提供可验证的中间步骤;
- 数据抽取管线:在离线环境下完成结构化信息提取;
- 检索增强生成(RAG):提供思考链路,提升答案可解释性。
获取方式
模型已在 Hugging Face 开源,提供多平台下载链接;同时可通过 OpenRouter、Liquid AI Playground、LEAP 边缘 AI 平台直接调用 API。企业用户亦可在自有服务器上自行部署。
LFM2.5-1.2B‑Thinking 的出现标志着 1 B 级推理模型在边缘计算中的一次质的跨越,为移动端 AI 应用打开了新的可能性。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。