AI算力全景CPU、GPU、TPU、NPU与LPU各领风骚
•46 阅读•3分钟•视野
GoogleNVIDIA算力AppleGroq
•46 阅读•3分钟•视野
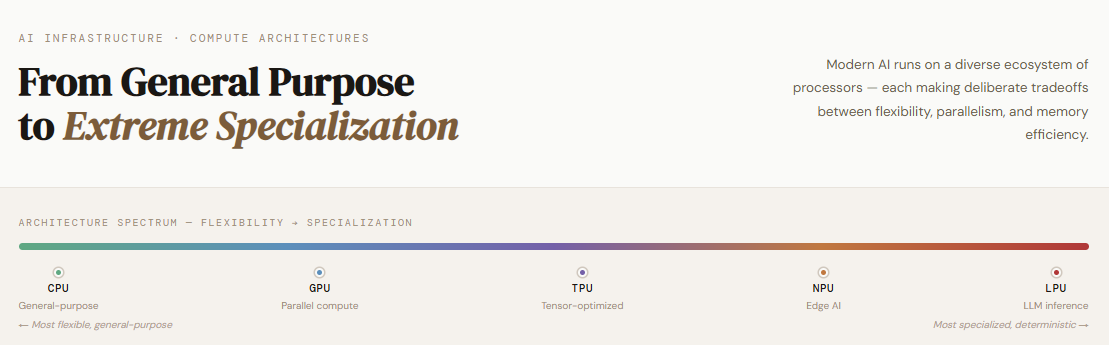
CPU – 通用控制中枢
- 定位:系统调度、数据流管理、通用计算。
- 优势:高频单核、深层缓存、成熟编程模型,几乎所有软件都能直接运行。
- 局限:并行度受限,矩阵乘法等大规模张量运算效率低,易成为训练与推理的瓶颈。
GPU – 并行加速核心
- 起源:最初用于图形渲染,凭借CUDA等平台转向通用计算。
- 优势:成千上万的轻量核心,擅长大规模矩阵乘法,已成为深度学习训练的主力军。
- 挑战:成本高、功耗大,对编程要求较高,面对复杂逻辑或低并行度任务时效率不佳。
TPU – 谷歌专属张量引擎
- 设计:采用矩阵乘法单元(MXU)和 systolic array,数据在芯片内部流水式流动,极大降低内存访问延迟。
- 优势:在大规模训练与云端推理上比GPU拥有更高的能效比,深度集成于Google Cloud服务。
- 局限:生态相对封闭,主要支持TensorFlow、JAX以及通过XLA的PyTorch,且大多只能通过云租用。
NPU – 边缘低功耗推理
- 代表:Apple Neural Engine、华为昇腾、Intel NPU等。
- 优势:专为8位及更低位宽算子设计,功耗在单数字瓦特级别,可实现实时语音、图像等本地推理。
- 局限:灵活性不足,难以承担大模型训练,仅适用于推理或轻量模型。
LPU – Groq的语言专用加速器
- 创新:全部权重与中间数据驻留在片上SRAM,编译期确定执行路径,实现零缓存失效、确定性延迟。
- 优势:在LLM推理场景下可比传统GPU快数倍,能效提升最高达10倍。
- 权衡:片上存储有限,需要通过多芯片拼接来支撑超大模型,生态仍在建设中。
异构系统的最佳实践
- CPU+GPU:适用于大模型训练,CPU负责调度与数据预处理,GPU完成核心张量运算。
- CPU+TPU:在Google Cloud上运行大规模训练或批量推理时,可获得最佳性价比。
- CPU+NPU:移动端或IoT设备的本地AI功能首选,降低网络带宽依赖。
- CPU+LPU:对实时LLM对话或搜索场景要求极低延迟时,可考虑部署LPU集群。
结语:AI算力已进入高度异构化阶段,单一处理器无法兼顾灵活性、并行度与能效。工程师应依据业务特性在CPU、GPU、TPU、NPU与LPU之间进行组合,才能在成本与性能之间找到最佳平衡。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。