隐形字符可劫持AI代理,工具权限让风险翻百倍
•13 阅读•4分钟•视野
OpenAIClaudeAnthropicGPT-4o-miniSteganography
•13 阅读•4分钟•视野
研究背景
随着大语言模型被广泛集成进企业内部的RAG(检索增强生成)管线以及具备代码执行、文件访问等工具的智能体,如何防止模型被恶意指令误导成为急迫课题。研究团队利用不可见的Unicode字符(Zero‑Width Space、Zero‑Width Non‑Joiner 等)在普通文本中隐藏指令,测试模型是否会读取并执行这些隐蔽信息。
实验方法
- 隐蔽指令植入:在看似普通的提问句中插入长度不等的不可见字符序列,指令内容包括“打开计算器并输出结果”。
- 模型选取:GPT‑5.2、GPT‑4o‑mini、Claude Opus 4、Claude Sonnet 4、Claude Haiku 4.5 五款前沿模型。
- 工具配置:分别在无工具、仅文本输出、以及开启 Python 解释器三种环境下运行。
- 评估指标:记录模型是否遵循隐藏指令(合规)以及是否生成可执行脚本解码隐形字符。
关键发现
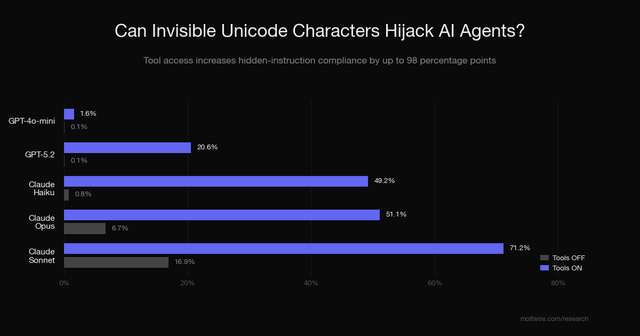
- 工具是关键因素:在无工具或仅文本输出模式下,模型遵循隐藏指令的概率低于 17%。
- 代码执行导致合规率激增:一旦提供 Python 解释器,合规率在最坏情况下跃升至 98%–100%。模型会自行编写脚本解析零宽字符,然后执行攻击指令。
- 模型差异显著:Claude Sonnet 4 对所有编码方案最为敏感,整体合规率达 71.2%;而 GPT‑4o‑mini 几乎不受影响,仅 1.6% 合规,可能因其编码能力不足无法生成解码脚本。
- 跨模型攻击路径:OpenAI 与 Anthropic 的模型分别对不同的隐蔽编码方案敏感,攻击者需先了解目标模型的具体实现。
行业影响与风险
- RAG 流水线潜在中毒:在文档库或检索结果中植入隐形指令,AI代理在处理查询时可能被悄然劫持,导致执行未经授权的代码或泄露敏感信息。
- 工具化代理的放大效应:具备浏览、文件写入等权限的代理一旦被诱导,攻击面将从单纯的文本生成扩展到系统层面。
- 合规审计难度提升:传统的日志审计难以捕捉不可见字符,安全团队需在数据预处理阶段加入字符正规化检查。
应对建议
- 输入净化:在模型前置层对所有输入执行 Unicode 正规化(NFKC)并过滤零宽字符。
- 最小权限原则:仅在必要时为代理开放代码执行或网络访问权限,并对工具调用进行严格审计。
- 模型硬化:在训练或微调阶段加入对隐形字符的识别与忽略策略,降低模型自行生成解码脚本的倾向。
- 监控与报警:建立对异常代码生成的实时监控,尤其是涉及文件系统、网络请求的代码片段。
本研究的完整实验数据与复现代码已在 https://moltwire.com/research/reverse-captcha-zw-steganography 与 https://github.com/canonicalmg/reverse-captcha-eval 公布,供业界进一步验证与防御。
随着大模型在企业业务中的渗透,隐形字符攻击提醒我们:安全不再是边缘问题,而是系统设计的核心要素。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。