可观测性成就可靠智能体:从调试思路到系统评估全链路揭秘
•35 阅读•3分钟•视野
LangSmithAgentObservabilityTrace
•35 阅读•3分钟•视野
背景
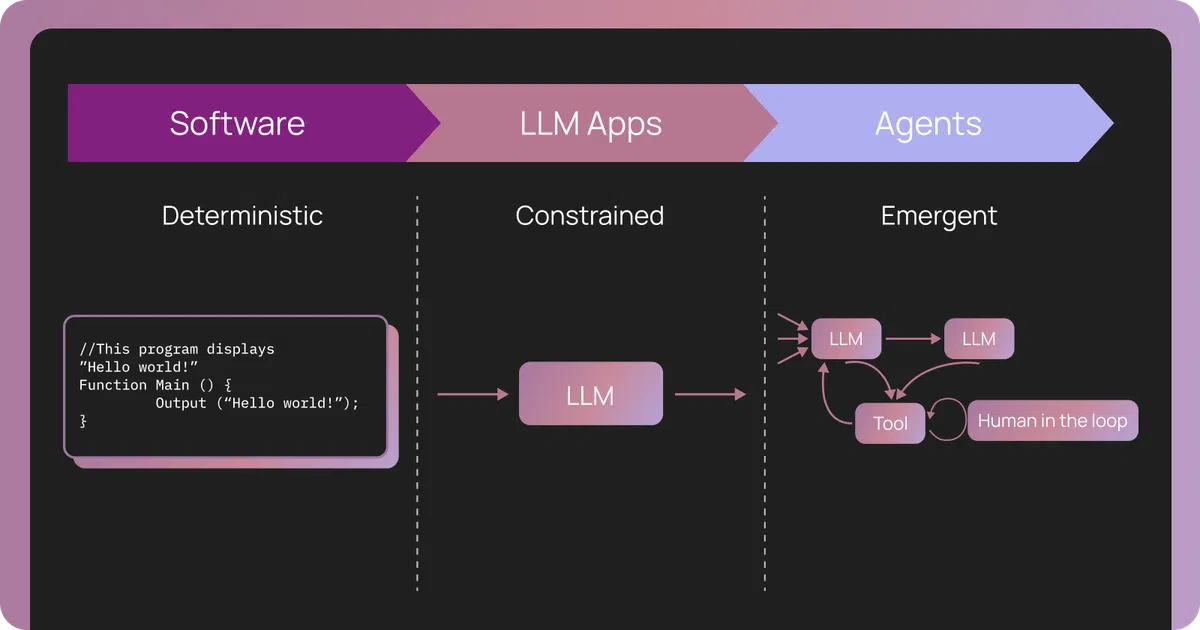
随着大语言模型(LLM)从单次调用演进为多轮工具调用的智能体(Agent),调试方式也随之根本转变。传统软件的错误定位依赖堆栈追踪和错误日志,而智能体的失误往往出现在推理链路的某一步——没有代码错误,只有决策错误。
可观测性 vs. 传统可观测性
- 确定性 vs. 不确定性:传统系统在相同输入下产生相同输出,日志即可定位问题。智能体的每一步受自然语言提示、上下文状态以及工具返回的影响,行为本质上是概率性的。
- 观测原语:
- Run:一次 LLM 调用,完整记录输入 Prompt、工具列表、模型输出。
- Trace:将所有 Run 按执行顺序链接,形成一次完整任务的轨迹。
- Thread:跨多次 Trace 的会话上下文,捕获长期记忆与状态演化。
这些原语与分布式系统中的 Span 类似,但侧重捕获 推理上下文 而非仅服务调用时延。
评估粒度的对应关系
| 评估层级 | 对应原语 | 典型场景 |
|---|---|---|
| 单步评估 | Run | 验证智能体在特定步骤是否调用了正确工具(如 find_meeting_times 而非 schedule_meeting)。 |
| 完整任务评估 | Trace | 检查任务执行路径、最终答案质量以及状态变更(文件编辑、数据库写入)。 |
| 多轮会话评估 | Thread | 确认上下文记忆是否在跨轮对话中保持一致(如用户偏好在后续请求中被正确引用)。 |
实践中的评估策略
- 离线评估:基于历史 Trace 构建测试集,使用断言或 LLM‑as‑judge 自动打分。适用于单步和完整任务的回归检测。
- 在线评估:在生产环境实时抽取 Trace,执行参考‑free 检查(工具调用模式、耗时异常、质量阈值),即时发现新型失效模式。
- 临时分析:当用户报告异常时,检索对应 Trace,定位错误步骤并快速生成对应的单步测试用例,实现“错误 → 复现 → 修复”闭环。
案例:从 Trace 到修复的完整流程
- 用户反馈智能体在第 11 轮误删文件。
- 在 LangSmith 平台检索到该 Thread,发现第 6 步的 Run 将错误信息写入记忆。
- 基于第 6 步的 Run 创建单步测试,断言记忆写入的内容必须符合预定义 schema。
- 调整 Prompt,使模型在写入前进行 schema 验证,全部回归测试通过后上线。
结论
智能体的可靠性不再是代码层面的校验,而是对 推理轨迹 的系统化观察与评估。通过统一的可观测性原语(Run、Trace、Thread),团队能够在离线、在线以及即时调试三个维度形成闭环,真正实现从“调试思路”到“系统评估”的全链路保障。
推荐工具:LangSmith 提供端到端的 Run/Trace/Thread 捕获、可视化以及评估框架,帮助团队快速落地上述实践。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。