阿里巴巴发布Qwen3-Max-Thinking 原生工具驱动的万亿参数推理模型
模型概述
Qwen3-Max-Thinking 是阿里巴巴最新的旗舰推理大模型,基于千亿级参数的 MoE 架构,预训练数据规模达 36 万亿 token。模型上下文窗口高达 260k token,能够一次性处理仓库级代码、长篇技术报告以及多文档分析。该模型以闭源方式提供,用户通过 Qwen‑Chat 与阿里云 Model Studio 的 OpenAI 兼容 HTTP API 进行调用。
体验累计测试时扩展策略
传统的测试时扩展(Test‑time Scaling)往往通过并行多链路采样提升答案质量,但算力随采样数线性增长。Qwen3-Max-Thinking 引入 体验累计(experience cumulative)策略:
- 在单轮对话结束后提取中间推理结果;
- 将有价值的子结论保存为经验,后续轮次聚焦未解决的子问题;
- 通过 API 参数
enable_thinking与预算字段动态调节思考深度。
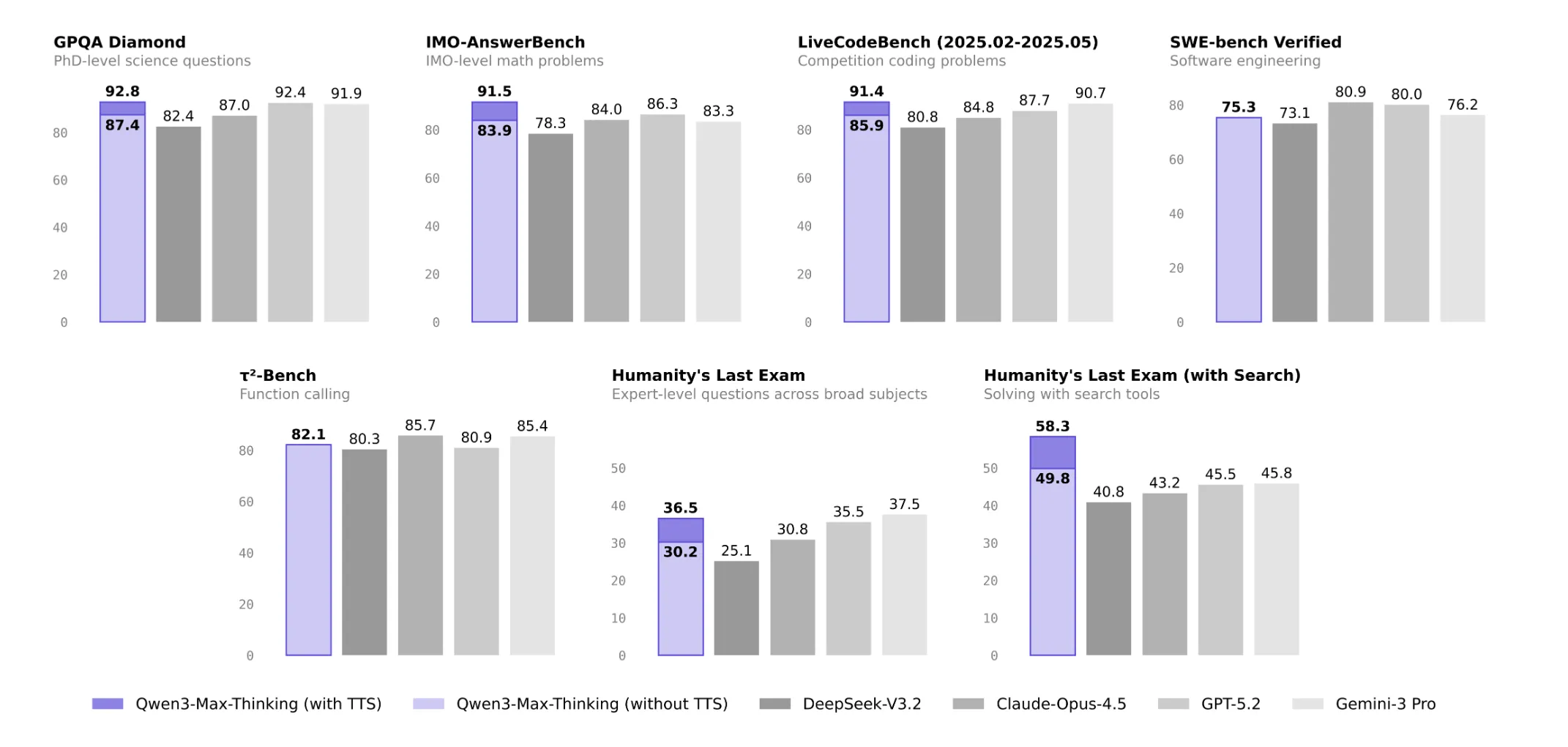
此方式在保持相近 token 消耗的前提下,将 GPQA‑Diamond 准确率从约 90 提升至 92.8,LiveCodeBench v6 从 88.0 提升至 91.4,展示了算力调度效率的显著提升。
原生工具与自适应调用
Qwen3-Max-Thinking 将 搜索、记忆、代码解释 三大工具作为模型内部能力:
- Search:实时网页检索,获取最新信息并进行内容抽取;
- Memory:会话级状态持久化,支持跨轮次的个性化推理;
- Code Interpreter:内置 Python 运行环境,可完成数值验证、数据转换与程序合成。
模型采用自适应工具调用(Adaptive Tool Use),在内部思考段落与工具调用交替进行,避免外部路由或规划器的额外开销,显著降低幻觉风险。Tau² Bench(功能调用与工具编排)得分 82.1,已接近同类前沿模型水平。
基准表现与竞争格局
在 19 项公开基准测试中,Qwen3‑Max‑Thinking 的表现与 GPT‑5.2‑Thinking、Claude‑Opus 4.5、Gemini 3 Pro 持平或略有优势。关键成绩包括:
- MMLU‑Pro 85.7、MMLU‑Redux 92.8、C‑Eval 93.7(中文评测领跑);
- GPQA 87.4、HMMT Feb 25 25 % 98.0、Nov 25 % 94.7、IMOAnswerBench 83.9;
- LiveCodeBench v6 85.9、SWE Verified 75.3。
在开启工具的 HLE(Human‑Level Evaluation)设置下,模型得分 49.8,超过同类 GPT‑5.2‑Thinking(45.5)和 Gemini 3 Pro(45.8),在最激进的体验累计配置下甚至达到 58.3。
市场意义与使用方式
Qwen3‑Max‑Thinking 的发布标志着阿里巴巴在大模型推理与工具化方向的全链路突破。通过 API 即可接入现有 Claude‑style 或 Anthropic‑style 工作流,企业可在无需自行搭建工具路由的情况下,实现搜索增强、记忆持久化与代码自动化三位一体的智能体(Agent)能力。该模型的高效算力利用与长上下文特性,特别适用于企业级文档分析、代码审计、科研报告撰写等需要深度、多轮推理的场景。
欲了解更多技术细节或获取 API 访问权限,请访问 Qwen 官方博客并关注阿里云模型平台的最新公告。