Arcee AI发布Trinity Large 400B MoE模型 打造美国本土开源大模型新标杆
•27 阅读•3分钟•前沿
NVIDIA开源Arcee AITrinity Large
•27 阅读•3分钟•前沿
背景与动机
Arcee AI成立于2023年,最初专注于为企业提供后训练(post‑training)定制服务。随着国外大模型几乎全被中国实验室占据,Arcee 决定在美国本土搭建完整的预训练(pre‑training)能力,以满足对数据合规、隐私安全有严格要求的企业客户。
Trinity Large 关键规格
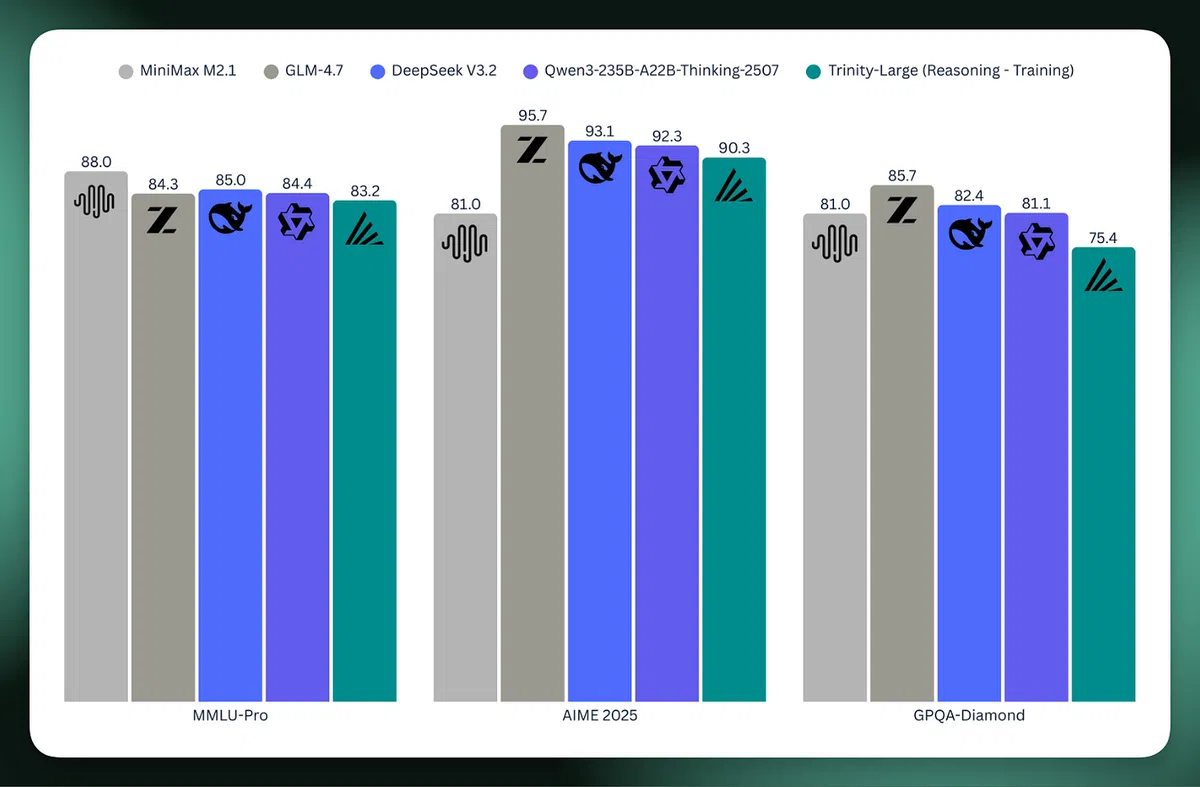
- 模型规模:总参数400B,稀疏激活13B(Mixture‑of‑Experts)
- 训练数据:约17万亿 token,约2300B后训练数据用于指令微调
- 硬件平台:22,048 块 NVIDIA B300(Blackwell)GPU,部分阶段使用 5,120 块 H200/H100 进行后训练
- 训练成本:约 2000 万美元,涵盖算力、薪资、数据、存储与运维
- 开放协议:Apache 2.0,商业使用无需额外授权费用
训练细节与技术创新
- 优化器:采用 Muon 优化器,内存占用比 Adam 低 30%,收敛速度提升约 15%
- MoE 架构:256 个专家(expert),每条 token 仅激活 1/20 的专家,显著降低推理算力需求
- 数据管线:与 Datology 合作构建多语言、多模态混合数据集,重点强化数学、代码与长文本推理
- 后训练策略:在同一集群完成 SFT 与 RLHF,使用 DeepSeek 的 Auxiliary‑loss‑free 方法平衡专家负载
商业模式转型
Arcee 将原有的 SaaS 定制收入暂时置后,全部资本(约 65%)投入模型研发。模型发布后,公司计划通过以下方式实现盈利:
- 企业级部署服务:提供私有化部署、技术支持与定制微调;
- API 计费:在 OpenRouter、独立 API 网关上提供付费调用,兼容 OpenAI、Anthropic 接口规范;
- 开源工具变现:MergeKit、DistillKit、EvolKit 等工具采用双许可证模式,保持社区活跃的同时收取企业版费用。
行业意义
- 美国本土开源生态:首次在美国完成 400B 规模的 MoE 开源训练,填补了国内外模型供应链的空白。
- 算力成本示范:在 B300 机器上完成全流程训练,展示了相较于 H100 系列更高的性价比,为后续模型迭代提供参考。
- 竞争格局:Arcee 表明即使是创业公司,也能在六个月内从 4.5B 到 400B 完成跃迁,对 Meta、Mistral 等传统开源力量形成新的挑战。
“我们把所有资本都投入到模型本身,只要模型足够好,后续的商业化自然会跟上。” — Mark McQuade, Arcee AI CEO
Arcee 计划在 2026 年底前继续扩展 Trinity 系列,推出更高效的 Mini/ Nano 版本以及专注垂直领域的定制模型,力争在全球开源大模型排行榜中占据领先位置。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。