DSGym推出容器化基底,统一评测千级数据科学代理任务
背景
近年来,随着大型语言模型(LLM)在代码生成与数据分析上的突破,数据科学代理(Data Science Agents)成为研究热点。然而已有基准如 QRData、DAEval 等往往隐藏数据文件,使模型通过文本模式匹配即可取得高分,无法真实衡量其数据处理能力。为此,斯坦福、哈佛、杜克以及 Together AI 的研究团队推出 DSGym,旨在提供一个“容器化‑代码‑评测”三位一体的统一平台。
框架概述
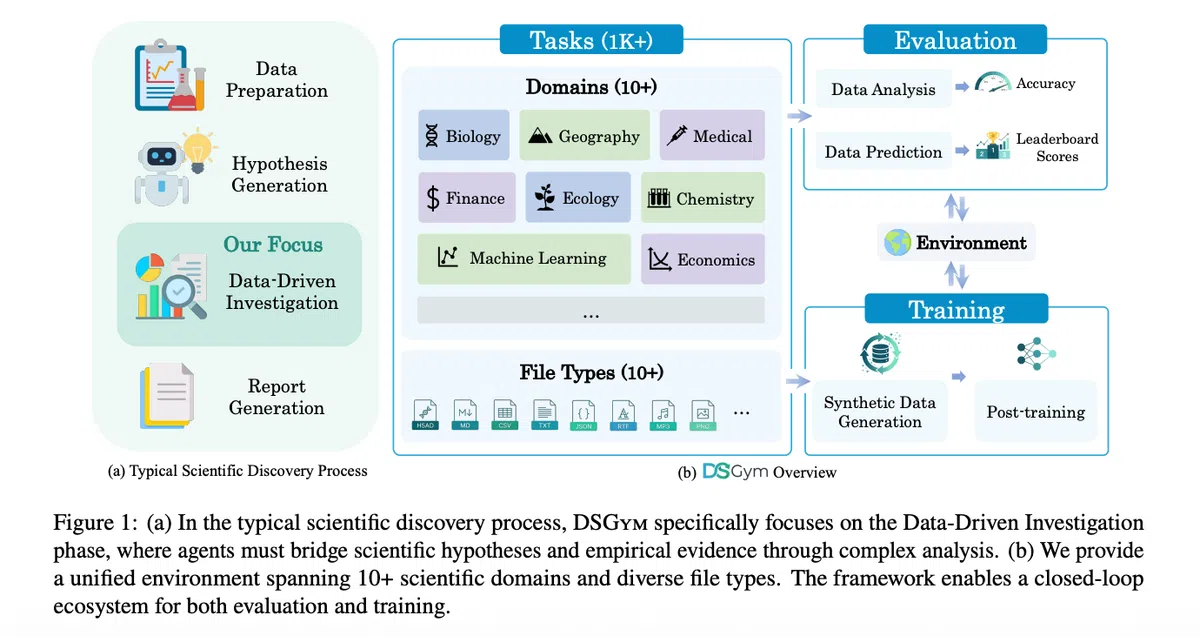
DSGym 将评测拆解为 Task、Agent、Environment 三大对象:
- Task:分为 Data Analysis(提供文件+自然语言问题)和 Data Prediction(提供训练/测试划分及评估指标)。
- Agent:遵循 CodeAct 循环——先给出推理块,再执行代码块,最后输出答案块。
- Environment:基于 Docker 容器的管理‑工作节点集群,所有数据以只读卷挂载,工作区可写,并预装领域专用 Python 库。
这种设计保证了每一次代码执行都在隔离且可复现的环境中进行,避免了跨任务污染。
任务与数据集
在原有基准的基础上,DSGym 对 QRData、DAEval、DABStep、MLEBench Lite 等进行清洗,剔除无法评分或可通过纯文本解答的题目,形成 DSGym‑Tasks。此外新增两大子集:
- DSBio:90 条来源于生物信息学论文的任务,覆盖单细胞、空间组学等,提供确定性数值或分类答案。
- DSPredict:从近期 Kaggle 比赛爬取的 92 项真实预测挑战,分为 Easy(38 项)和 Hard(54 项)。
整体规模达 972 条数据分析任务 + 114 条预测任务。
评测结果
使用统一的 CodeAct 代理(温度 0、禁用工具)对多种模型进行评测,主要包括:
- 闭源模型:GPT‑5.1、GPT‑5、GPT‑4o
- 开源大模型:Qwen3‑Coder‑480B、Qwen3‑235B‑Instruct、GPT‑OSS‑120B
- 小模型:Qwen2.5‑7B‑Instruct、Qwen3‑4B‑Instruct
关键发现
- 在清洗后的通用分析基准(QRData Verified、DAEval Verified)上,前沿模型的 Exact Match 介于 60%‑90%。
- 在 DSBio 上,最高准确率仅 43.33%(Kimi‑K2‑Instruct),且 85‑96% 的错误源于领域库使用错误或生物学解释失误。
- 在 DSPredict Easy 中,主流模型的有效提交率超过 80%;但在 Hard 中,超过 70% 的模型难以提交有效结果,Kaggle 排名几乎为零。
- 结果显示模型普遍存在 简易性偏差:在可行的基线解答后停止探索,更复杂的模型调参与特征工程仍显不足。
训练与提升
DSGym 同时提供合成数据生成管线:从 QRData 与 DABStep 中抽取子集,让代理自行探索数据、提出问题并记录完整轨迹,生成约 3,700 条查询‑轨迹对。经 Judge 模型筛选后得到 2,000 条高质量的 DSGym‑SFT 数据。基于此微调的 4B Qwen3 模型在标准分析基准上已能逼近 GPT‑4o 的水平,证明 执行‑感知监督 是提升数据科学代理的有效路径。
影响与展望
DSGym 为学术界与工业界提供了一个可复用、可扩展的评测生态:
- 统一标准:任务、代理、环境三层抽象消除了不同基准之间的碎片化。
- 真实代码驱动:评测过程完全基于容器化代码执行,确保答案可验证、可复现。
- 数据工厂:合成轨迹生成与过滤机制为小模型提供了高质量的微调数据,降低了大模型依赖的门槛。
未来,随着更多领域(如金融、气候科学)数据集的加入,以及更强大的工具集成(如自动特征工程、超参数搜索),DSGym 有望成为数据科学代理研发的核心基准平台。
本文基于作者在 MarkTechPost 的报道及原始 arXiv 论文(https://arxiv.org/pdf/2601.16344)整理。