Sakana AI与NVIDIA推出TwELL稀疏格式 实现LLM推理加速20% 训练提速22%
背景
大语言模型(LLM)的前馈层占据超过三分之二的参数量和80%以上的计算 FLOPs,是成本的主要瓶颈。虽然激活稀疏在理论上已被广泛观察,但传统稀疏格式(如 ELLPACK)在 GPU 上往往因额外的转换开销而抵消收益,导致实际加速有限。
技术创新
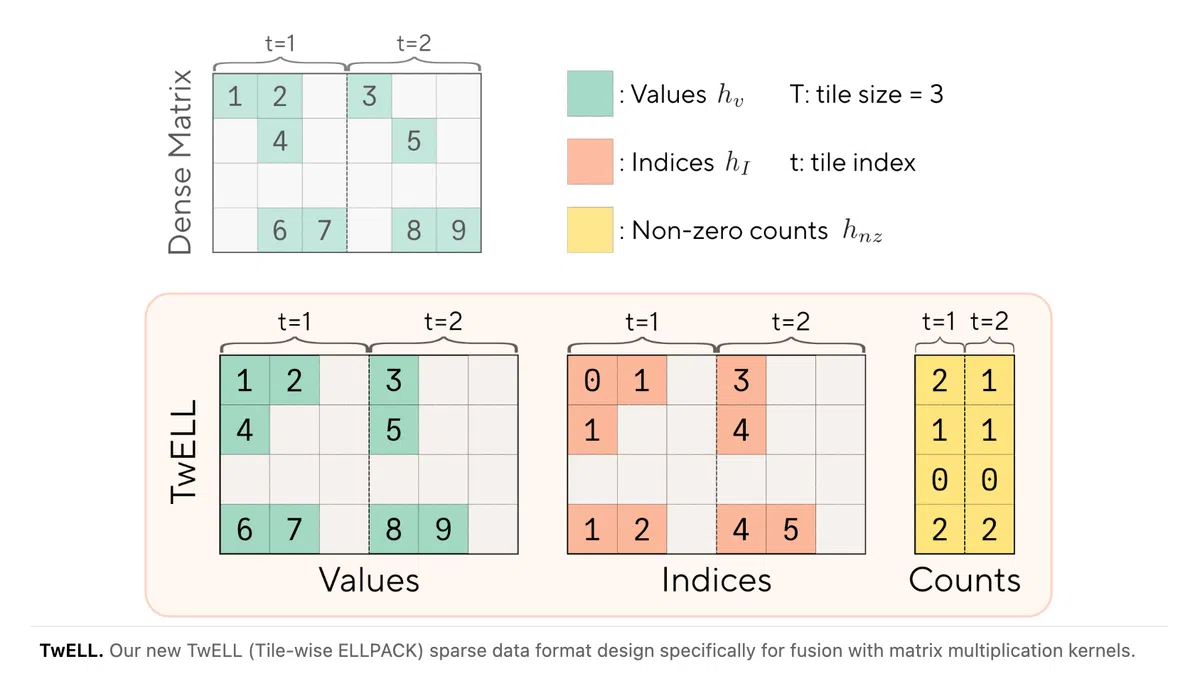
TwELL(Tile‑wise ELLPACK) 通过与 CUDA 矩阵乘法内核的 tile 大小对齐,在投影核的 epilogue 直接构建稀疏表示,无需额外 kernel 或全局同步。其核心思路包括:
- 将列划分为与 matmul tile 同尺寸的水平块;
- 在每个块内部局部压缩非零值及索引;
- 采用混合稀疏格式:稀疏行使用紧凑 ELL,溢出行回退至密集备份。
这种设计使得推理阶段只需一次融合 kernel 完成 gate 激活读取、上投影与下投影,隐藏状态从不写回显存,显著削减 DRAM 访问。
训练与推理加速方案
- 激活函数改为 ReLU,保证负值直接产生零。
- 在所有层的隐藏激活上加入 L1 正则项(系数 2×10⁻⁵),不改变学习率、权重衰减等其他超参。
- 稀疏度在约 1,000 步(≈10⁹ token)后快速收敛,超过 99% 的激活为零。
实验结果
| 模型规模 | 推理加速 | 训练吞吐提升 | 能耗下降 | 记忆占用下降 |
|---|---|---|---|---|
| 0.5B | +17.0% | -11.8% | -1.5% | -19.2% |
| 1B | +18.1% | -14.6% | +7.1% | -25.5% |
| 1.5B | +18.8% | -15.0% | +11.6% | -28.1% |
| 2B | +20.5% | +21.9% | -17.0% | -22.3% |
所有实验均在单节点 8 块 H100 PCIe GPU、序列长度 2048 的设置下完成。规模越大,平均非零激活数越低(0.5B 为 39,2B 为 24),稀疏 kernel 跳过的计算比例随之提升,效率提升呈线性增长。
在 RTX PRO 6000(188 SM)上,同样观察到更大幅度的加速,说明该方案对非专用硬件亦具备显著收益。
开源与生态
项目代码、稀疏格式实现以及训练脚本已在 GitHub 完全开源,兼容主流 gated‑feedforward LLM(如 Llama、Qwen)以及非 gated 变体。文档提供了“一键启用”指南:仅需将激活函数替换为 ReLU,添加 L1 正则项,即可在现有训练流水线中获得 20% 以上的加速。
社区声音:多位业界研究者在 Reddit AMA 中表示,TwELL 的 tile‑wise 思路为 GPU 稀疏计算提供了可落地的实现路径,预计将在下一代大模型训练框架中得到广泛采纳。
展望
未来工作将聚焦于将稀疏化技术迁移至已有的密集预训练模型,以及在多模态大模型中探索更细粒度的稀疏模式。若成功,模型部署成本有望进一步下降,为中小企业的本地化推理打开新局面。