NVIDIA发布Star Elastic 单一检查点容纳三种规模推理模型
•46 阅读•3分钟•前沿
生成式AINVIDIANemotronStar Elastic
•46 阅读•3分钟•前沿
背景
大型语言模型(LLM)家族通常需要为每个参数规模单独训练、存储和部署,这导致算力、存储和运维成本呈线性增长。为破解这一瓶颈,NVIDIA研究团队在Nemotron Nano v3基础上提出了Star Elastic,一种后训练的弹性模型框架,能够在一次训练中生成多层次子模型,并统一保存为单一检查点。
核心技术
- 嵌套权重共享:通过重要性估计对模型组件(嵌入通道、注意力头、Mamba SSM、MoE专家、FFN通道)进行打分,按贡献度排序。子模型始终使用排名最高的连续子集,实现了从大模型到小模型的自然嵌套。
- 可学习路由器:使用Gumbel‑Softmax生成可微分掩码,根据目标预算(如2.8B活跃参数)输出对应子模型结构,训练过程与主模型联合进行,避免了传统压缩方法的固定剪枝。
- 多轴弹性:支持在嵌入维度、注意力头数、MoE专家数、SSM维度等多个维度上同步压缩,提供更细粒度的模型裁剪能力。
训练效率
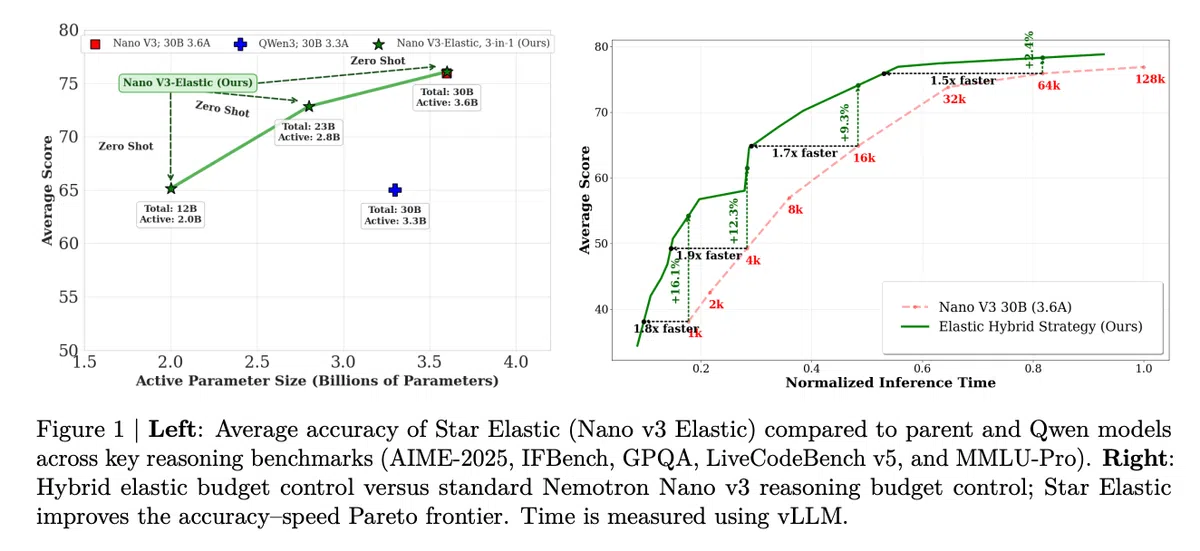
Star Elastic在Nemotron Nano v3(总参数30B,活跃参数3.6B)上一次性训练出30B、23B(2.8B活跃)和12B(2.0B活跃)三种变体,仅使用约1600亿token。相较于为每个规模单独预训练,训练token量降低 360倍,算力成本下降超 7倍。
弹性预算控制
传统推理采用统一模型完成"思考+回答"两阶段,Star Elastic提出 小模型思考‑大模型回答(ℳS→ℳL)策略。以23B模型生成长链推理,再交由30B模型合成最终答案,可在准确率提升 最高16% 的同时,将推理延迟降低 1.9倍,显著优化了准确率‑延迟的Pareto前沿。
量化与部署
- FP8 PTQ:对30B变体进行后训练量化,恢复 BF16 精度的 98.69%。
- NVFP4 QAD:针对 NVIDIA 自研 4‑bit 浮点格式,先做 PTQ 再进行约 5B token 的量化感知蒸馏,恢复精度至 97.79%。
- 存储优势:三种规模的 BF16 检查点总计 126.1 GB,Elastic 单检查点仅 58.9 GB;NVFP4 版本 30B 仅 18.7 GB,能够在 RTX 5080 等消费级显卡上运行 12B 变体。
行业意义
Star Elastic展示了通过宽度弹性而非深度裁剪实现的高效压缩路径,为大模型家族的训练、部署提供了全新范式。研发团队无需为每个规模维护独立的训练流水线,也不必为不同推理阶段手动切换模型,大幅降低了研发成本和上线门槛。随着模型规模继续扩张,此类弹性技术有望成为算力受限环境(如边缘推理、企业内部部署)的关键支撑。
“通过一次训练即可得到多尺度模型,并在推理阶段灵活切换,Star Elastic 为生成式AI的商业化落地提供了更具弹性的技术选项。”—— NVIDIA AI 研究团队
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。