Google推出Gemma 4多令牌预测草稿器 实现三倍推理加速
•18 阅读•3分钟•前沿
GoogleLLMGemma 4MTPSpeculative Decoding
•18 阅读•3分钟•前沿
背景
大语言模型在生成文本时采用自回归方式——一次只产生一个 token。虽然算力本身已大幅提升,但每一步都需将数十亿参数从显存搬入计算单元,导致 内存‑带宽 成为真实的性能瓶颈。尤其在预测容易的 token 时,模型仍会执行完整的前向计算,造成算力闲置和延迟累积。
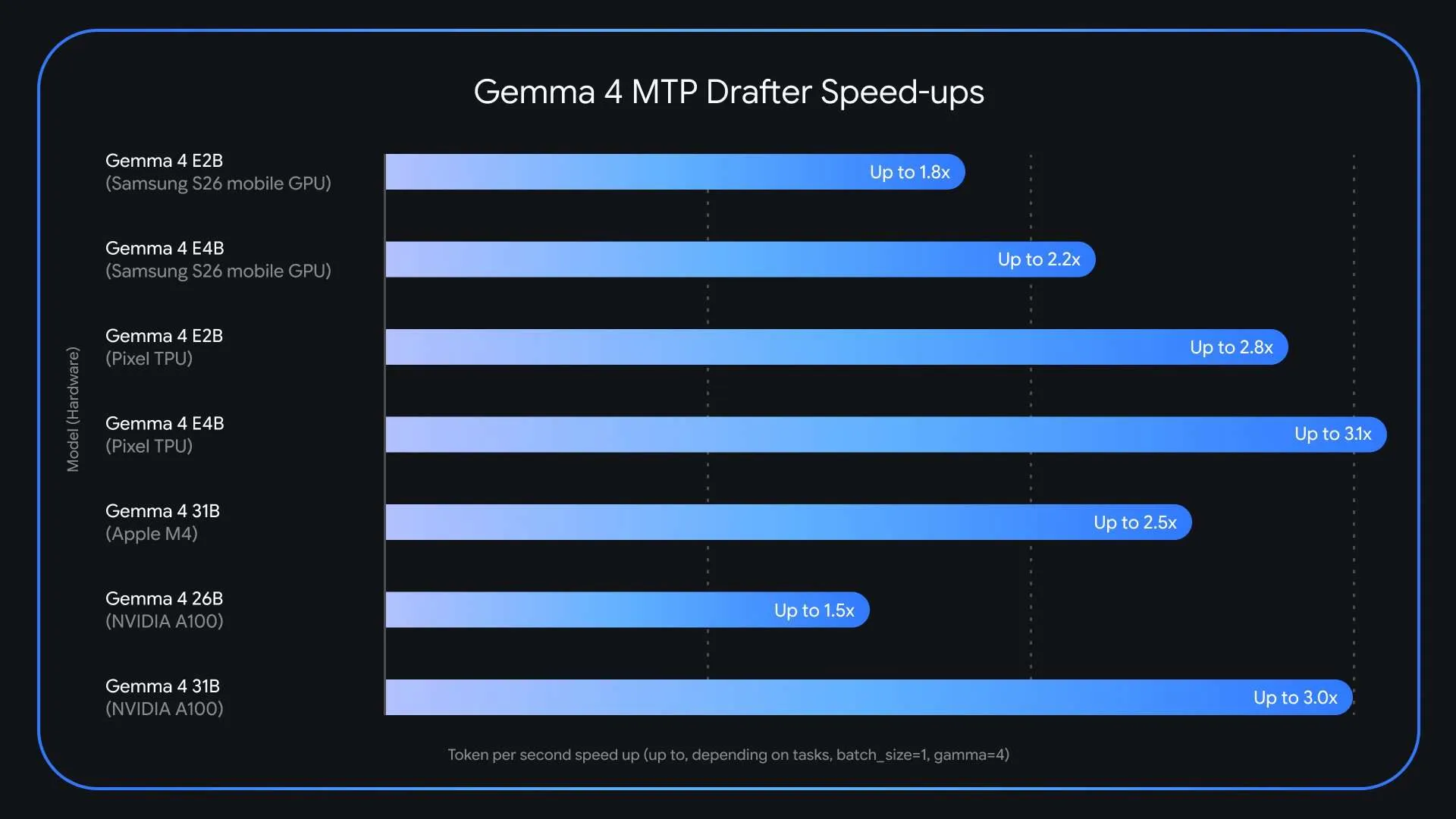
MTP 草稿器技术概览
Google 为 Gemma 4 系列引入 Multi‑Token Prediction(MTP)草稿器,其核心是 Speculative Decoding:
- 轻量草稿模型 先在极短时间内预测出若干后续 token,形成 draft 序列。
- 目标模型(如 Gemma 4 31B) 同时对整段 draft 进行一次前向验证。若全部匹配,目标模型直接接受该序列,并额外生成一个 token。
- 草稿模型共享目标模型的 KV cache(键值缓存),避免重复计算上下文。
对于 Edge 版的 E2B/E4B,Google 进一步在嵌入层引入 高效聚类,加速最后的 logits 计算,专门解决内存受限设备的瓶颈。
性能表现
- 在标准 GPU(NVIDIA A100)上,批量大小从 1 提升至 4‑8 时,可获得约 2.2× 的本地加速;
- 在 Apple Silicon 单卡下,使用 Gemma 4 26B MoE 模型,同样的批量调优实现约 2× 提速;
- 综合测试显示,整体推理速度最高可达 3×,而输出质量(BLEU、准确率)与原始模型无差别,属于 无损加速。
发行与生态
MTP 草稿器已通过 Apache 2.0 协议开源,模型权重同步上架 Hugging Face 与 Kaggle,开发者可直接下载并在现有推理框架中替换。Google 同时提供了配套的 API 示例,帮助企业快速集成至生产服务。
业界意义
此举标志着 LLM 推理进入 投机解码 的成熟阶段,尤其对需要低延迟、成本敏感的业务(如实时对话、搜索增强)提供了可行方案。通过在不牺牲质量的前提下大幅压缩算力需求,MTP 可能促使更多中小企业能够在本地或边缘设备上部署高容量模型,进一步推动生成式 AI 的产业落地。
"MTP 让我们在保持模型原始能力的同时,突破了单 token 生成的天花板。" — Google AI 团队
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。