Meta推出Autodata框架 让AI模型自主管理高质量训练数据
背景与动机
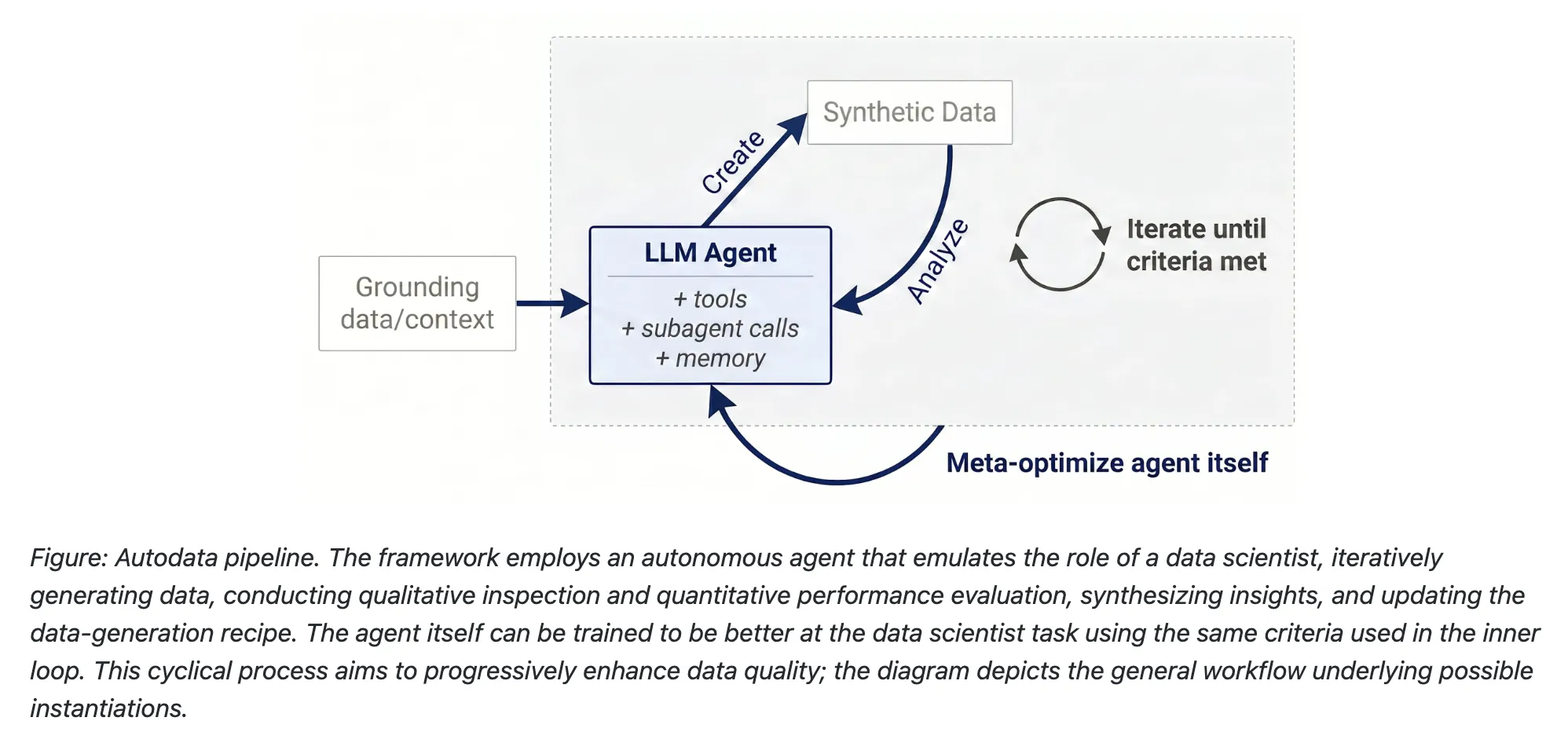
构建更强大模型的瓶颈并非算力,而是训练数据的质量。传统流程依赖人工标注或一次性合成,缺乏对生成过程的闭环反馈。Meta RAM团队基于这一痛点,提出 Autodata,将 AI 代理化为“自主数据科学家”,在生成‑评估‑迭代的循环中不断提升数据质量。
Autodata 框架核心机制
Autodata 将数据生成任务拆解为四个子代理,并由主协调模型 orchestrate:
- Challenger LLM:依据主模型提供的详细提示,生成候选训练样例(输入+输出)。
- Weak Solver:能力受限的模型,预期在该样例上表现不佳,用以衡量问题难度。
- Strong Solver:更强的模型,预期能够解答该样例,用以评估模型提升空间。
- Verifier/Judge:依据 Challenger 生成的评分标准,对两者输出进行质量打分,形成多条件接受准则。
接受准则包括:
- 弱模型平均得分 ≤ 65%,且最高得分 ≤ 75%;
- 强模型平均得分 ≥ 60% 且 < 95%;
- 两者分差 ≥ 20%;
- 以上全部满足方可纳入数据集。
若未达标,Verifier 会向 Challenger 反馈具体改进方向,循环迭代直至满足条件或耗尽预算。该闭环将推理算力直接转化为更高质量的数据。
实验结果与性能提升
在 10,000 余篇计算机科学论文(S2ORC)中,Autodata 产出 2,117 条符合严格质量要求的 QA 对。相较于传统 CoT Self‑Instruct,实验得到以下关键提升:
- 弱模型得分从 71.4% 降至 43.7%;
- 强模型得分从 73.3% 提升至 77.8%;
- 两者分差扩大至 34 分点,显著提升数据的区分度。
使用该数据对 Qwen‑3.5‑4B 进行一次 epoch 微调(batch‑size 32、lr 1e‑6),在同分布与跨域测试集上均超越基准合成数据的表现。
元优化与自动改进
Autodata 进一步支持对“数据科学家代理”本身的元优化。通过演化式搜索,对代理的提示、代码脚手架和评估逻辑进行自动改写,累计 233 次迭代中 126 次被采纳,验证通过率从 12.8% 提升至 42.4%。关键改进包括:
- 论文特定性约束:确保问题必须依赖特定论文内容;
- 上下文泄漏防护:禁止在描述中出现论文的解决方案;
- 正向权重 rubric:去除负权重评分项,避免削弱强模型得分;
- 结构化 JSON rubric:统一评分标准格式,降低解析错误。
这些自动化改进显著降低了人工工程成本,为大规模高质量合成数据提供了可复制的路径。
行业影响与展望
Autodata 展示了“推理算力 → 数据质量” 的新范式,预示着未来合成数据生成将从单次生成转向持续自我改进的闭环系统。对拥有海量算力的企业而言,可通过提升推理预算直接获得更优训练样本;对资源受限的团队,则可借助高效的自动化管线降低标注支出。Meta 进一步开放代码与实验数据,有望催生开源社区的二次创新,加速生成式 AI 的整体迭代速度。