Meta AI发布Sapiens2,实现千像素人形视觉全任务新突破
•55 阅读•4分钟•前沿
MetaSapiens2Pose EstimationSegmentation3D Geometry
•55 阅读•4分钟•前沿
背景与挑战
在人形计算机视觉领域,姿态捕捉、细粒度分割以及三维几何恢复长期受限于分辨率和特征表达的矛盾。传统动作捕捉系统难以捕捉手指细节,分割模型常出现牙齿与牙龈混淆等现象。Meta Reality Labs指出,要在任意真实图像中一次性理解人体的结构、表面细节以及光照属性,需要突破两大瓶颈:
- 高分辨率感知:细节只有在千像素乃至四千像素尺度才能被保留。
- 语义与几何统一:既要捕获低层纹理,又要学习高层人体语义,防止表示漂移。
Sapiens2的核心创新
- 双目标预训练:在Masked AutoEncoder (L_MAE) 与全局对比学习 (L_CL) 上加权融合,保持像素级细节的同时提升语义一致性。
- 学生‑教师框架:基于DINOv3,教师参数采用学生的指数滑动平均 (EMA),确保全局特征不受强增强扰动。
- 层次化窗口注意力:前K层局部窗口自注意力捕获细纹,随后通过CLS‑引导的池化降采样进行全局注意力,兼容MAE掩码策略。
- 高效算子:RMSNorm 取代 LayerNorm、Grouped‑Query Attention (GQA) 与 QK‑Norm 提升大尺度训练稳定性,SwiGLU 前馈层进一步加速。
"Sapiens2是首个在千像素原始分辨率下全任务同步提升的专用人体模型,展示了大规模视觉Transformer的极限潜能。" – Meta AI 研究团队
数据规模:Humans‑1B
从约40 亿网络图像中多阶段过滤,最终得到1 十亿高质量人形图像。过滤流程包括
- 人体检测与头部姿态估计
- 美学与真实感评分
- CLIP特征过滤
- 文本覆盖检测
随后采用感知哈希与深度特征最近邻去重,按姿态、视角、服装、光照等维度进行平衡抽样,确保数据多样性。预训练阶段未使用任何任务标签,仅依赖纯图像信息。
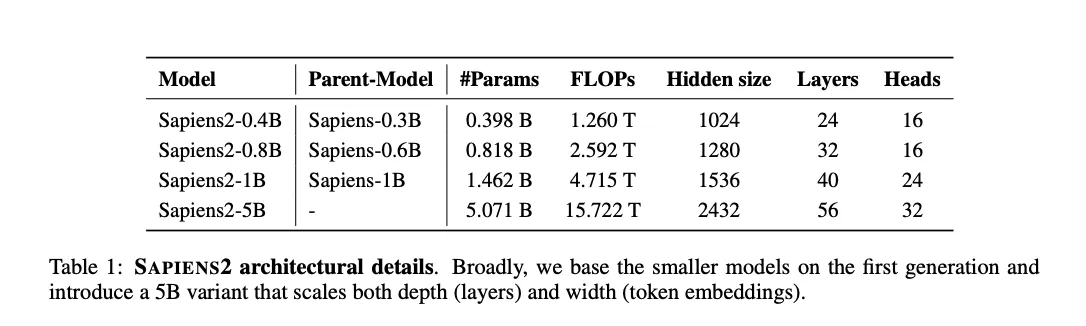
模型规格与性能
| 模型 | 参数量 | 原生分辨率 | FLOPs (TFLOPs) | 关键任务提升 |
|---|---|---|---|---|
| Sapiens2‑0.4B | 0.4 B | 1K | 1.2 | +21.3 mIoU (分割) |
| Sapiens2‑5B | 5 B | 1K | 15.7 | +4 mAP (姿态) |
| Sapiens2‑1B‑4K | 1 B | 4K | 12.4 | +0.9 mIoU (分割) |
任务细节
- 姿态估计:308 关键点全身骨架,面部 243 点、手部 40 点,100 K 野外标注提升泛化。
- 部位分割:29 语义类别(新增眼镜),使用加权交叉熵 + Dice 损失。
- 点图估计:直接回归相机坐标系下的 3D 点云,每像素提供深度信息。
- 法线估计:像素级法线预测,0.4B 模型 MAE 为 8.63°,5B 模型降至 6.73°。
- 反照率估计:在合成高保真数据上训练,MAE 0.012、PSNR 32.61 dB,准确恢复皮肤与服装本色。
在统一冻结骨干、仅训练轻量解码头的密集探测评估中,Sapiens2‑5B 超越所有基线,包括参数更大的 DINOv3‑7B,展示了专用人体模型的强大迁移能力。
业界意义
Sapiens2的发布为元宇宙、虚拟人物、AR/VR 交互以及高精度运动捕捉提供了统一的视觉基础设施。其千像素原生分辨率意味着在实际摄像头输入下即可获得细粒度几何信息,降低了后处理的成本和误差累积。与此同时,Meta 开源了模型权重与演示代码,为学术界和工业界的二次创新奠定了平台。
展望:随着更大规模数据与算力的持续投入,人形视觉模型有望进一步融合光照估计、材质推断以及跨模态语言描述,推动生成式人形内容的全链路自动化。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。