DeepMind推出Vision Banana统一视觉模型,零样本超越SAM 3与Depth Anything V3
•49 阅读•3分钟•前沿
DeepMindVision BananaNano Banana ProSAM 3Depth Anything V3
•49 阅读•3分钟•前沿
研究背景
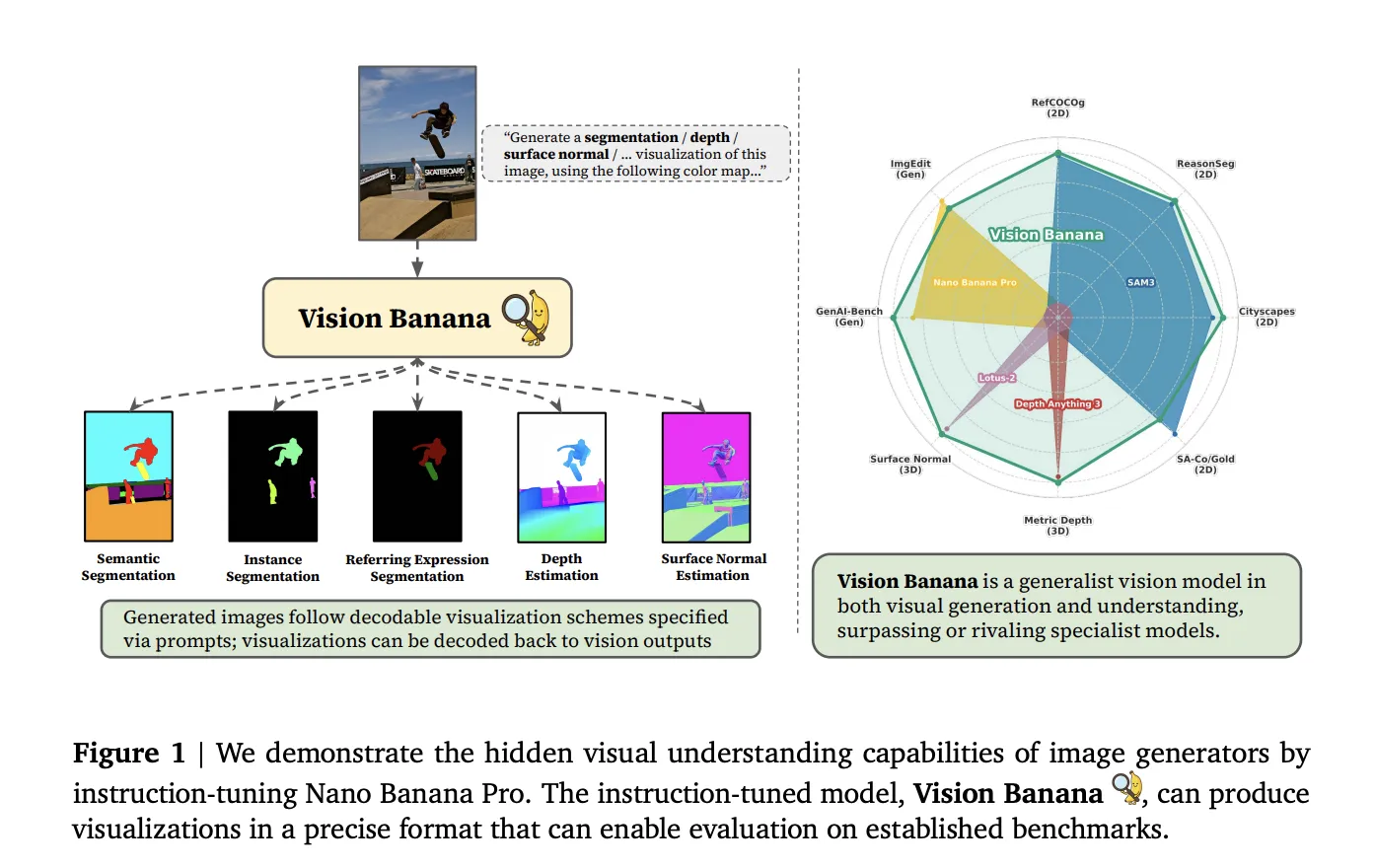
长期以来,计算机视觉社区在生成模型和判别模型之间保持两条平行路线,前者负责图像合成,后者负责图像理解。DeepMind 的新论文《Image Generators are Generalist Vision Learners》(arXiv:2604.20329)提出,生成式预训练同语言模型的预训练一样,能够为视觉任务提供通用表征。团队在 2026 年 4 月 22 日正式发布了 Vision Banana,这是一款在 Nano Banana Pro 基础上进行轻量指令微调的统一模型。
方法概述
- 生成式预训练即通用视觉学习:Nano Banana Pro 采用大规模文本‑图像对进行生成式训练,模型在学习真实感图像的过程中自然捕获几何、语义和深度信息。
- 指令微调把所有视觉任务映射为 RGB 图像:通过在原始训练混合中加入极少量的视觉任务数据,并在提示中规定颜色映射规则,模型仅需改变提示即可输出语义分割、实例分割、度量深度或表面法线的可解码 RGB 图。
- 完全无任务专用头:所有任务共享同一套权重,推理时只需替换提示词,无需额外模块或相机参数。
零样本实验结果
- 语义分割(Cityscapes val):mIoU 0.699,超越 SAM 3 的 0.652。
- 实例分割(SA‑Co/Gold):pmF1 0.540,接近 DINO‑X(0.552),显著领先 Gemini 2.5(0.461)。
- 度量深度(六大基准):δ₁ 平均 0.882;在 Depth Anything V3 评测的四个数据集上达到 0.929,优于其 0.918。
- 表面法线(四大基准):平均角度误差 18.93°,低于 Lotus‑2 的 19.64°,室内数据集上更是 15.55° 的最佳成绩。
- 生成能力保持:在 GenAI‑Bench 文本‑图像基准中,Vision Banana 对 Nano Banana Pro 的胜率为 53.5%,在 ImgEdit 中为 47.8%,说明指令微调未削弱原有生成性能。
关键意义与未来方向
Vision Banana 的成功证明,图像生成预训练能够自动学习通用视觉表征,进而在无需专用架构或大量标注数据的情况下完成多种感知任务。这为“基础视觉模型”(Foundational Vision Model)的概念提供了实验证据,未来可能出现类似 LLM 的统一接口:通过不同提示实现图像理解、编辑、测量等多模态交互。DeepMind 表示,后续将探索更大规模的生成式预训练以及跨模态指令微调,以进一步提升模型在实际工业场景中的鲁棒性和可解释性。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。