DeepMind推出Decoupled DiLoCo 打破大模型分布式训练瓶颈实现88%高效利用率
•47 阅读•3分钟•前沿
算力DeepMindTPUDecoupled DiLoCo分布式训练
•47 阅读•3分钟•前沿
背景与挑战
随着大模型参数规模突破百亿量级,传统的数据并行训练面临两大瓶颈:
- 同步阻塞:所有加速器在每一步梯度汇总时必须等待最慢节点,导致慢节点(或故障节点)拖慢整套系统。
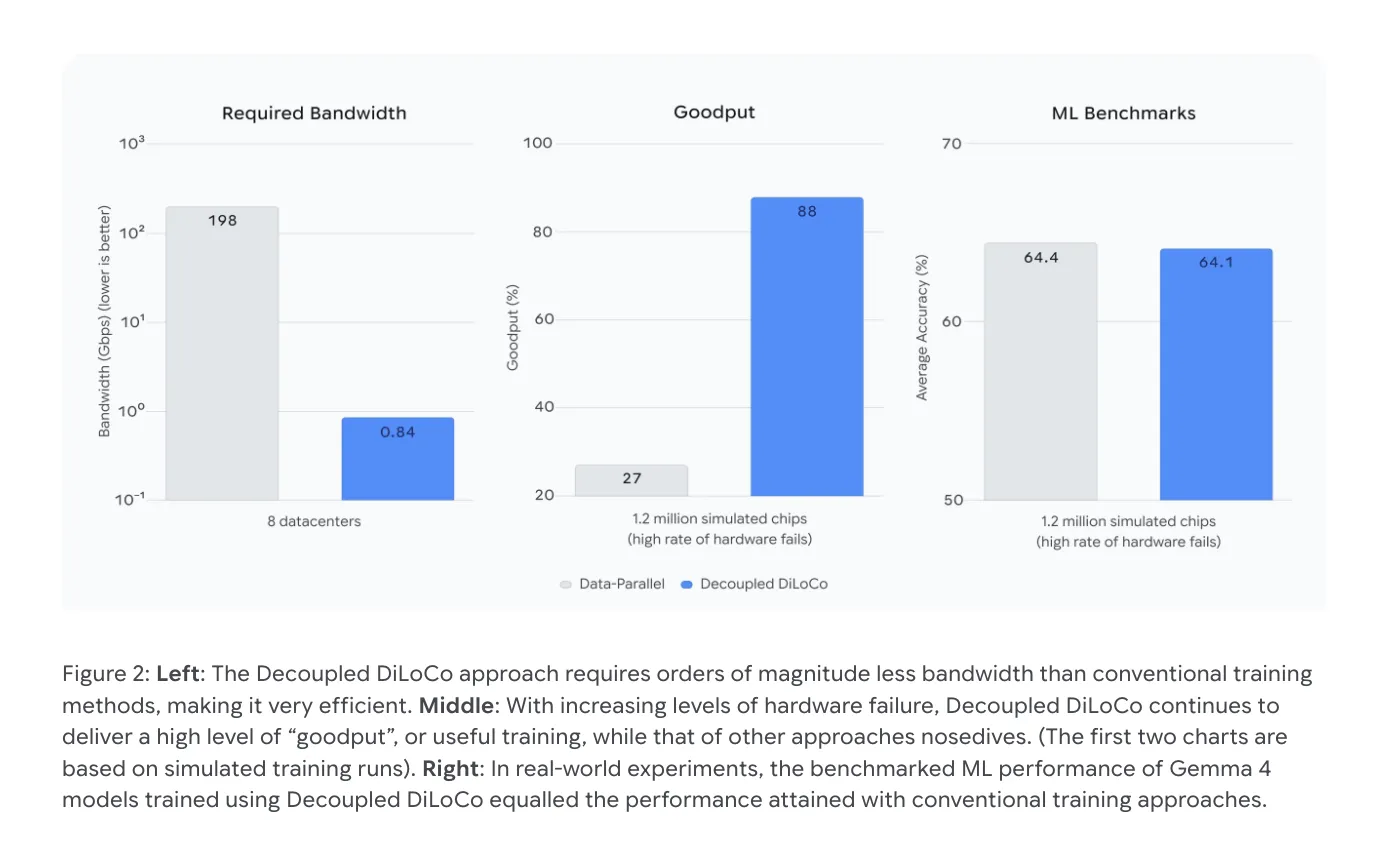
- 跨域带宽:在多地数据中心之间进行AllReduce,需要约198 Gbps的互联带宽,远超公网可提供的容量。
这些问题在数千甚至上万块芯片协同工作时尤为突出,直接限制了前沿模型的训练规模和成本。
Decoupled DiLoCo 核心思路
DeepMind 将此前的两项系统——Pathways 的异步数据流和 DiLoCo 的低通信策略——进行融合,提出 Decoupled DiLoCo(Distributed Low‑Communication)。其关键创新包括:
- 学习单元(Learner Unit):将加速器划分为若干独立的计算“岛屿”。每个岛屿内部进行多步本地梯度更新,仅在预设间隔向外部优化器发送压缩后的梯度。
- 异步全局聚合:外部优化器采用异步方式合并各岛屿的梯度,任何单个岛屿的失效或慢速都不会阻塞其他岛屿继续训练。
- 极大带宽压缩:通过本地多步累积和梯度压缩,将跨数据中心的带宽需求从198 Gbps削减至仅0.84 Gbps,足以在普通互联网层级上运行。
实验验证与性能表现
- 自愈能力:团队使用混沌工程在模拟环境中故意失效整批学习单元,系统仍保持 88% 的 Goodput(有效训练时间占比),远高于传统数据并行的 27%。
- 模型质量:在 Gemma‑4 基准上,Decoupled DiLoCo 达到 64.1% 的准确率,仅比标准基线的 64.4% 低 0.3%,基本在评估噪声范围内。
- 大规模实测:成功在美国四个地区使用 2‑5 Gbps 的宽带训练 12 B 参数模型,训练速度比传统同步方法快 20 倍以上。
- 硬件异构:实验混合使用 TPU v6e 与 TPU v5p,异构运行不影响最终模型性能,体现了对不同代际加速器的兼容性。
产业意义
- 降低算力门槛:跨数据中心的低带宽需求让中小企业或科研机构无需昂贵的专线,即可参与大模型预训练。
- 延长硬件寿命:异步架构容忍硬件代际差异,旧代 TPU 仍可在新项目中贡献算力,提升资本回报率。
- 提升可靠性:自愈特性降低了硬件故障对训练进度的影响,降低了大模型研发的运营风险。
展望
Decoupled DiLoCo 为大模型的全局分布式训练提供了全新的范式,未来可能在多模态模型、跨语言预训练以及大规模强化学习等场景进一步推广。DeepMind 已在官方博客公开了技术细节和源码实现,业界可据此开展二次研发或在自有算力平台上进行适配。
“在高故障率环境下保持接近 90% 的训练效率,是我们多年在系统容错和通信优化上的积累成果。” — DeepMind 研究团队
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。