DeepMind发布Gemini Robotics-ER 1.6提升机器人空间推理与仪表读取能力
•31 阅读•4分钟•前沿
Boston DynamicsDeepMind具身智能Gemini Robotics-ER 1.6Spot
•31 阅读•4分钟•前沿
关键发布
Google DeepMind在官方博客上正式推出 Gemini Robotics-ER 1.6,定位为机器人系统的高层认知模型。相较于1.5版,1.6在空间感知、任务规划、成功检测以及全新仪表读取能力上均有显著提升,为工业现场的自主检查提供了可落地的技术支撑。
双模型协同架构
- Gemini Robotics 1.5:视觉‑语言‑动作(VLA)模型,负责将视觉输入和指令直接转化为电机指令。
- Gemini Robotics‑ER 1.6:具身推理模型,专注于理解物理空间、制定计划并评估任务完成度,不直接控制机械臂。
两者的配合类似策划者‑执行者的关系:ER 提供高层决策,VLA 执行具体动作,实现了模块化、可扩展的机器人智能体系。
指向能力与空间推理
指向(pointing)是模型在像素级别定位目标的能力,远超传统目标检测。1.6版利用指向实现:
- 精确计数:在复杂场景中准确统计锤子、剪刀等物体数量。
- 关系推理:如“将最小的物体移动到蓝色杯子里”。
- 运动轨迹规划:通过指向确定抓取点和移动路径。
- 约束满足:识别所有能放入指定容器的物体。
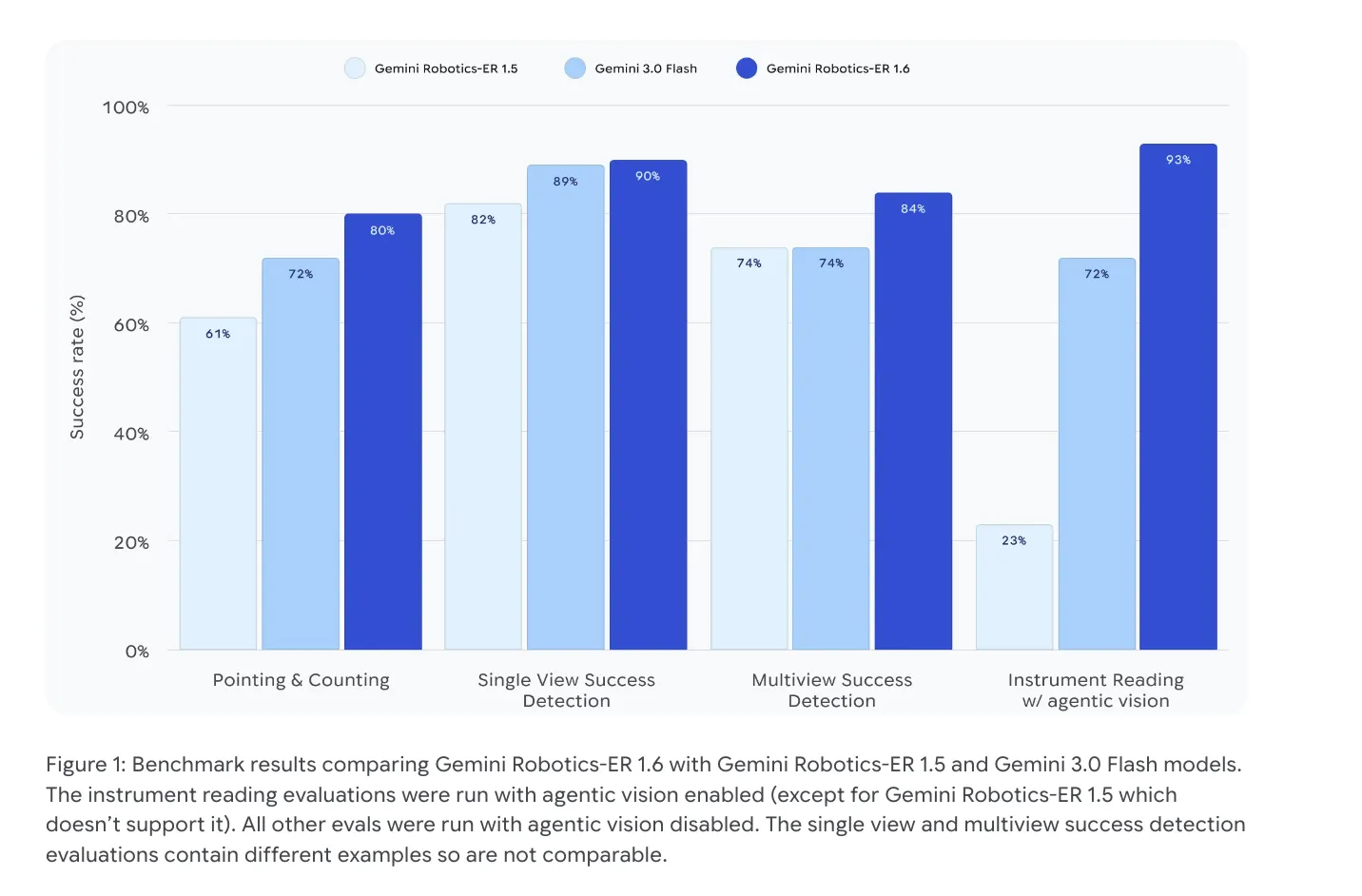
内部基准显示,1.6在这些任务上的准确率明显高于1.5,显著降低了机器人因误检导致的失误风险。
仪表读取的突破
仪表读取是本次更新的最大亮点。模型能够解析模拟仪表、压力表、视窗玻璃等工业读数,支持:
- 针式指针定位、刻度识别、文字单位读取。
- 结合代理视觉(agentic vision),先放大关键区域,再通过代码执行完成比例计算与单位换算。
在与波士顿动力(Boston Dynamics)Spot 机器人的合作实验中,1.6的仪表读取准确率达 93%(启用代理视觉),相比1.5的 23% 提升近四倍。此能力直接面向工业设施巡检、设备维护等高价值场景。
多视角成功检测
机器人往往配备俯视摄像头和腕部摄像头,需要跨视角融合信息判断任务是否完成。1.6在多视角推理上实现:
- 跨视角一致性校验:识别同一对象在不同摄像头下的对应关系。
- 遮挡处理:在部分视角被遮挡时仍能推断整体状态。
- 动态环境适应:实时更新场景模型,判断是否进入下一步骤。
成功检测的可靠性提升,使机器人能够自主决定是重试还是继续执行后续任务,推动真正的端到端自主操作。
业界意义与前景
Gemini Robotics‑ER 1.6的发布标志着具身智能在实际工业应用中的一次重要跃迁。它将高层认知与底层执行解耦,为 模块化机器人系统 提供了可复用的“大脑”。
- 对机器人研发团队而言,可直接调用该模型的 API,实现快速原型验证。
- 对工业用户来说,仪表读取和多视角成功检测降低了人工巡检成本,提升了安全性。
- 与 Boston Dynamics Spot 的合作示例展示了跨公司生态的协同潜力,预示未来更多机器人平台将集成类似认知模型。
总体来看,Gemini Robotics‑ER 1.6不仅是 DeepMind 在具身 AI 研究的里程碑,也为机器人行业的商业化落地提供了关键技术支点。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。