DeepMind推出统一潜空间框架显著提升生成质量与算力效率
•60 阅读•3分钟•前沿
生成式AIDeepMindUnified Latents视频生成
•60 阅读•3分钟•前沿
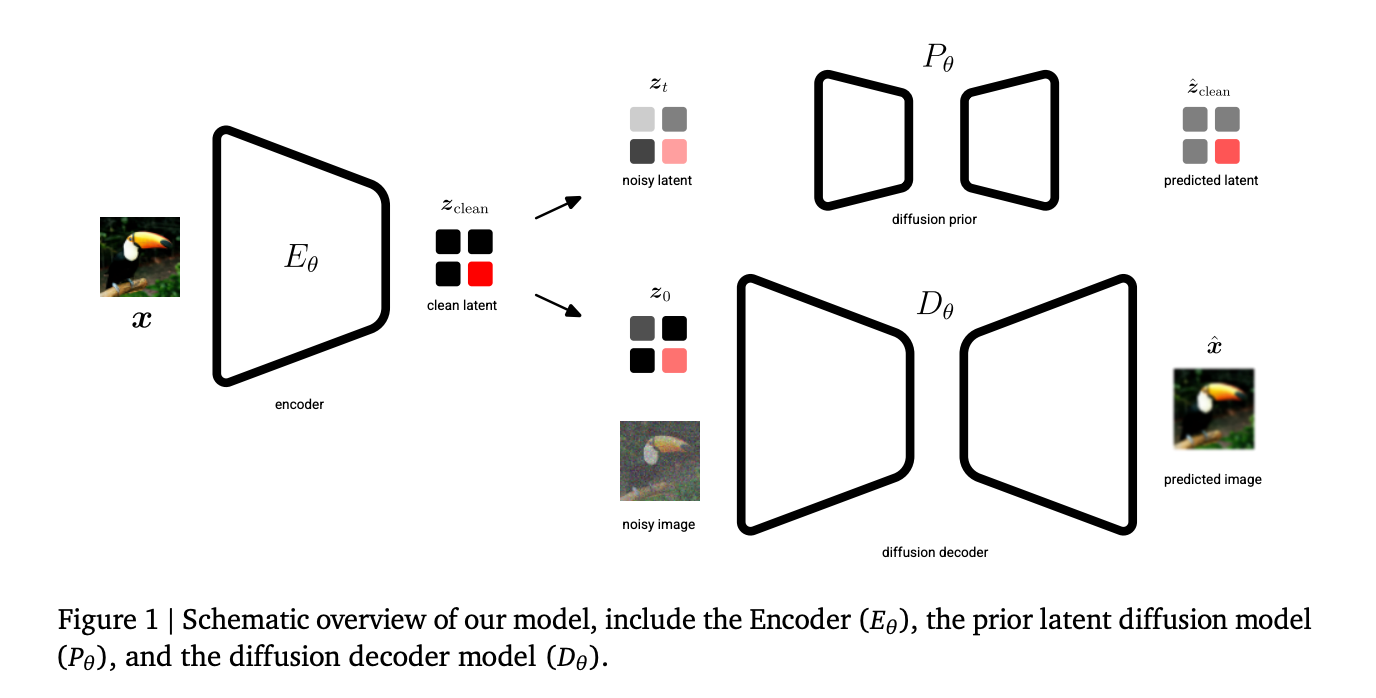
框架概述
DeepMind的Unified Latents(UL)是一套将潜空间编码、扩散先验与扩散解码器统一训练的框架。它通过在潜空间加入固定的高斯噪声,将潜表示的比特率上限显式化,从而在保证压缩率的同时提升生成质量。
三大技术支柱
- 固定高斯噪声编码:使用确定性编码器 (E_\phi) 直接预测干净潜向量 (z_{clean}),随后在固定的log‑SNR (\lambda(0)=5) 处加入噪声,形成统一的噪声基准。
- 先验对齐:扩散先验模型的噪声水平与编码器输出的最小噪声相匹配,使ELBO中的KL项简化为加权均方误差(MSE),便于解析潜比特率上界。
- 加权解码ELBO:解码器采用 sigmoid 加权损失,既提供了潜比特率的可解释上界,又允许模型在不同噪声层级上灵活分配学习资源。
两阶段训练流程
- 阶段一‑联合潜空间学习
- 同时训练编码器、扩散先验 (P_\phi) 与扩散解码器 (D_\phi)。
- 目标是让潜表示在被编码、正则化、建模三方面保持一致,形成紧凑且可扩散的潜空间。
- 阶段二‑基模型扩展
- 冻结编码器与解码器,仅在潜空间上训练更大的“基模型”。
- 通过 sigmoid 加权进一步提升样本质量,支持更大模型规模与更大批量训练。
性能评估与SOTA
| 数据集 | 关键指标 | UL结果 | 备注 |
|---|---|---|---|
| ImageNet‑512 | FID | 1.4 | 在相同计算预算下优于Stable Diffusion基线 |
| Kinetics‑600 | FVD | 1.3 (中型模型) / 1.7 (小型模型) | 创下视频生成新纪录 |
| ImageNet‑512 | PSNR | 30.1 dB | 高压缩率下仍保持出色重建 fidelity |
这些结果显示,UL在训练 FLOPs 与生成质量的关系上实现了显著提升,尤其在视频生成任务中首次突破 FVD 1.5 大关。
业界影响与展望
- 算力效率:通过固定噪声上界,UL 为潜空间压缩提供了明确的比特率控制,帮助研究者在算力受限的环境下仍能训练出高质量生成模型。
- 多模态扩展:框架本身并不限定于图像,可直接迁移至视频、音频等高维数据,预计将在生成式AI的多模态探索中发挥关键作用。
- 开源潜力:虽然当前实现仍在论文阶段,DeepMind 已在arXiv 公开全部代码与模型细节,社区有望快速复现并基于 UL 进行二次创新。
“Unified Latents 为潜空间建模提供了统一的数学视角,兼顾压缩与生成质量,是下一代扩散模型的核心基石。”——DeepMind 论文作者团队
整体来看,Unified Latents 为生成式AI在高分辨率图像与视频领域的算力-质量平衡提供了新范式,后续的开源实现与行业落地值得持续关注。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。