Perplexity发布pplx-embed双向注意力嵌入模型提升网页检索性能
•17 阅读•3分钟•前沿
RAG通义千问Perplexitypplx-embedINT8
•17 阅读•3分钟•前沿
背景
随着生成式AI的快速普及,检索增强生成(RAG)对高质量、低延迟的向量检索提出了更严苛的要求。传统的单向解码模型在处理长文本或噪声数据时往往表现欠佳,导致检索向量与实际语义出现偏差。Perplexity针对这一痛点,推出了专为网页规模检索设计的pplx-embed模型族。
模型创新
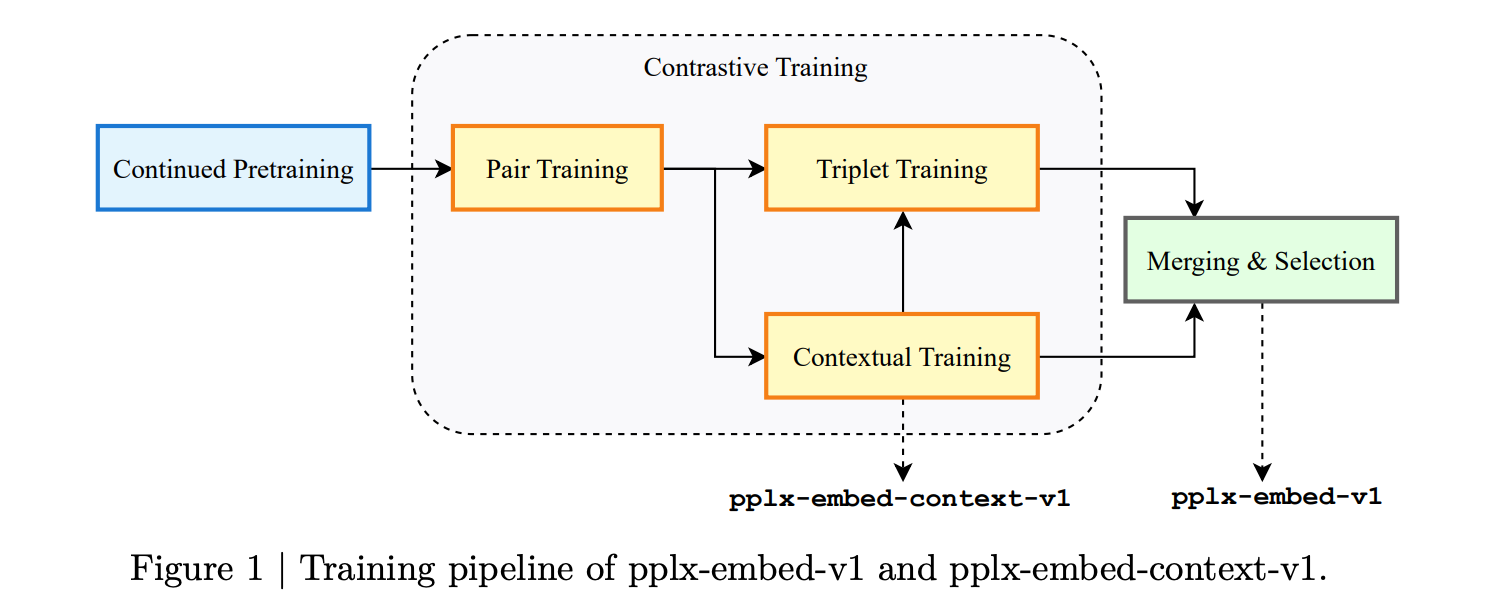
- 双向注意力(Bidirectional Attention):不同于大多数LLM的因果解码结构,pplx-embed采用全序列并行编码,使模型在一次前向传播中即可捕获句子完整上下文。
- 扩散预训练(Diffusion‑based Pretraining):借鉴图像生成中的扩散过程,将噪声文本映射回干净语义表示,提升对碎片化网页内容的鲁棒性。
- 基于Qwen3(通义千问):模型架构在通义千问的基础上改造,保持了其大规模多语言能力,同时针对嵌入任务做了结构性优化。
版本与性能
Perplexity提供两款针对RAG不同环节的模型:
- pplx-embed‑v1:面向独立查询和短文本,适合搜索引擎前端的实时向量化。
- pplx-embed‑context‑v1:专为文档块(如知识库段落)设计,能够在长文本中保持向量空间的一致性。
两款模型分别对应 0.6B 与 4B 参数规模,并原生支持 INT8 以及二进制量化,内存占用比同等精度的 FP16 模型降低 8‑32 倍,推理时延可控制在 10ms 以下,满足大流量在线服务的需求。
生产部署考量
- Matryoshka Representation Learning (MRL):允许在同一模型中动态裁剪向量维度,用户可根据业务成本自行权衡精度与计算。
- 开源权重 & 文档:模型权重已同步至 Hugging Face,配套的 API 文档与示例代码覆盖 Python、Rust 与 C++,便于快速集成至现有检索管道。
- 兼容性:支持与常见向量数据库(Milvus、Pinecone、FAISS)直接对接,且提供查询‑文档对齐的评估脚本。
行业意义
pplx-embed的发布标志着嵌入模型从单一“语言模型”向专用检索编码器的分化趋势。双向注意力加扩散预训练的组合,使模型在处理海量、噪声严重的开放网页时表现出前所未有的鲁棒性。对企业而言,能够以更低的硬件成本部署高质量向量检索,进一步降低对商业嵌入 API(如 OpenAI、Cohere)的依赖,加速生成式AI在搜索、问答与企业知识库等场景的落地。
“Embedding 的质量直接决定了 RAG 系统的上限,Perplexity 用技术创新把这条上限往上推了一个档次。” — Perplexity 研究团队
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。