ETH Zurich研究警示:冗长AGENTS.md文件让AI编码助手性能下降
•22 阅读•4分钟•前沿
GPT-5.2ETH ZurichAGENTS.mdContext Engineering
•22 阅读•4分钟•前沿
背景
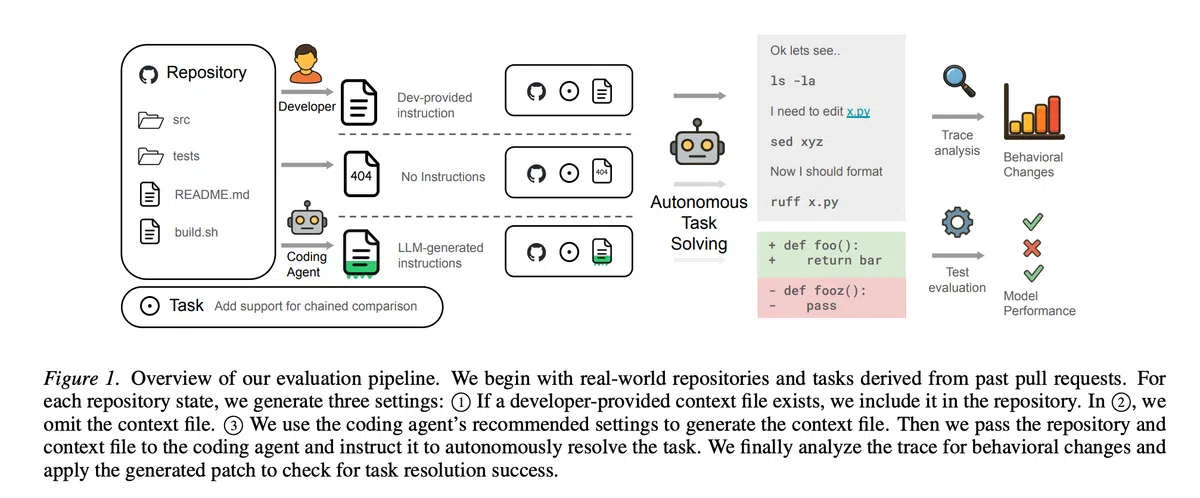
近日,ETH Zurich的研究团队在 arXiv 上公布了题为《Context Engineering for AI Coding Agents》的论文,系统评估了在代码库中使用 AGENTS.md(以及 CLAUDE.md 等)作为全局上下文文件对编码智能体表现的影响。
关键发现
- 成功率下降:自动生成的上下文文件使任务成功率平均降低约 3%;即便不使用任何上下文文件,成功率更高。
- 推理成本上升:注入上下文会导致推理费用增加超过 20%,并且需要更多的推理步数才能完成相同任务。
- 人工编写收益有限:人工编写的 AGENTS.md 仅带来约 4% 的成功率提升,提升幅度远低于其成本。
- 模型规模非关键因素:使用更强大的模型(如 GPT-5.2)生成上下文文件并未改善结果,模型内部已有足够的库知识,额外的上下文反而成为噪声。
为什么“好”上下文失效
研究指出,智能体对上下文文件中的指令极度服从。当指令与实际需求不匹配时,智能体会遵循冗余要求,从而消耗额外的推理 token,导致效率下降。常见的目录树、代码风格指南等信息在大多数情况下是多余的,因为模型能够自行发现文件结构并遵循项目的既有 lint/formatter。
新的上下文工程准则
必须包含(Vital Few)
- 技术栈与目标:简要说明项目使用的主要语言、框架以及核心业务目标,帮助模型快速定位关键组件。
- 非显而易见的工具链:明确标注特殊构建或测试工具(如
uv替代pip),研究表明明确提及的工具使用频率提升约 160 倍。 - 关键入口点:提供主要入口文件或关键接口的路径,便于模型直接定位。
必须排除(Noise)
- 详细目录树:省略完整的文件层级列表,模型自带的搜索能力足以定位所需文件。
- 代码风格规范:将代码风格交由自动化 linter/formatter 处理,避免在上下文中占用 token。
- 针对性极强的指令:除非任务明确需要,否则不要加入仅适用于极小子集的问题规则。
- 自动生成的内容:禁止让模型自行生成上下文文件,缺乏人工审校的文件往往噪声更大。
结构建议
- 行数控制:保持文件在 300 行以内,理想情况下不超过 60 行。
- 渐进披露:根文件仅提供指向子文件的链接(如
agent_docs/testing.md),在需要时再加载。 - 指针而非复制:使用
file:line形式的指针指向代码实现,避免代码片段随时间陈旧。
实践意义
- 对企业级开发团队而言,遵循上述准则可在保持模型性能的同时,将推理成本降低约 20%。
- 对模型研发者来说,研究提示了“上下文噪声”对智能体行为的负面影响,为未来的提示工程提供了新的方向。
“上下文越精简,模型越自由。”—— ETH Zurich 研究团队
结论
ETH Zurich 的实验表明,盲目堆砌 AGENTS.md 内容不仅无法提升 AI 编码助手的表现,反而会增加成本并降低成功率。通过聚焦关键信息、削减冗余、采用指针式引用,开发者可以实现更高效、更经济的代码生成与审查工作流。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。