Liquid AI发布LFM2-24B-A2B混合架构 兼顾注意力与卷积突破大模型算力瓶颈
•17 阅读•3分钟•前沿
Liquid AILFM2-24B-A2BSparse MoE混合架构GQA
•17 阅读•3分钟•前沿
核心亮点
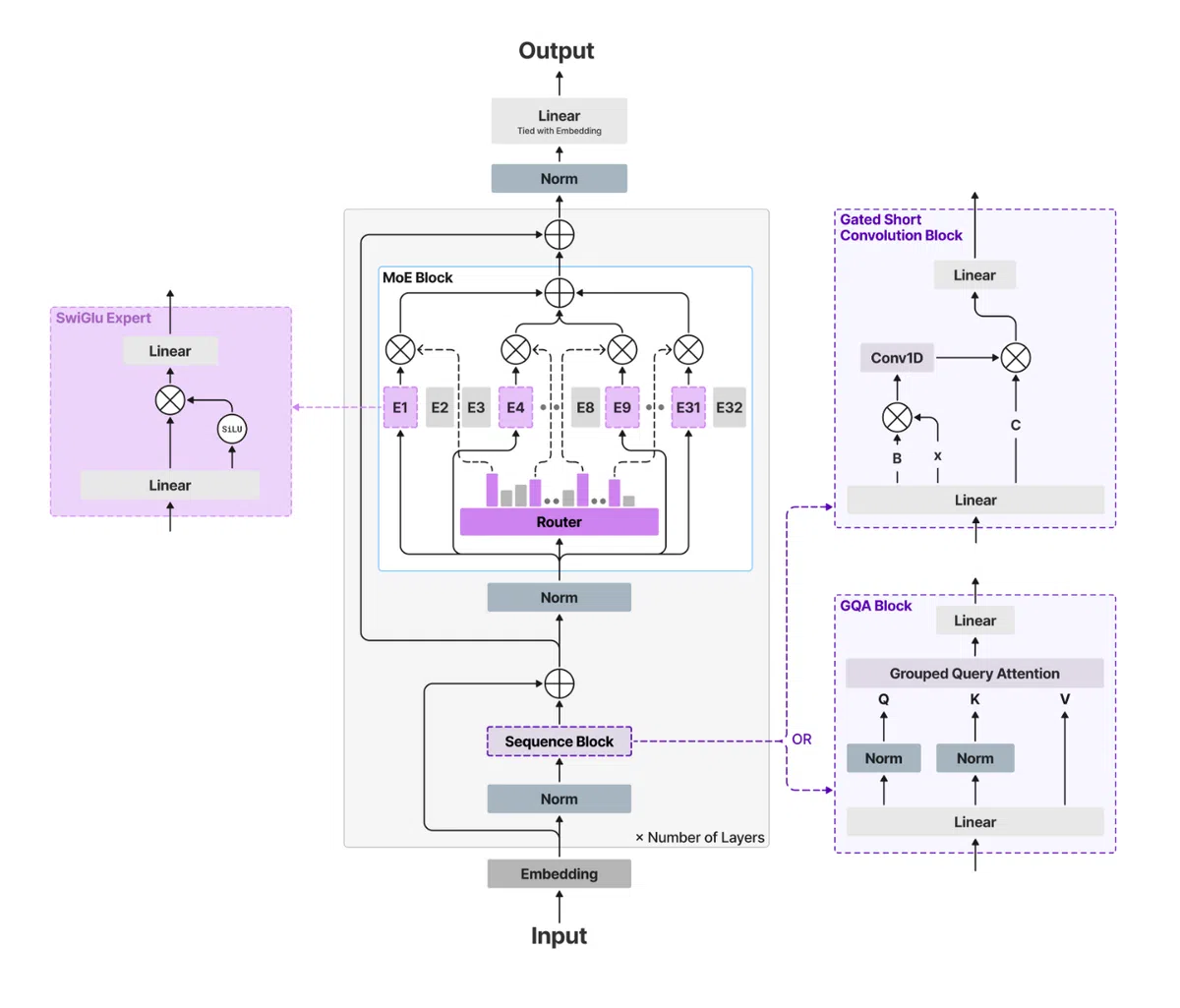
Liquid AI最新发布的 LFM2-24B-A2B,是一种将注意力层与门控短卷积层相结合的混合架构(Hybrid Architecture),旨在缓解传统Transformer在序列长度上呈二次增长的算力瓶颈。
A2B 架构概览
- 比例设计:模型共40层,其中30层为高效卷积(Base)层,10层为 Grouped Query Attention(GQA)层,形成 1:3 的Attention‑to‑Base比例。
- 线性复杂度:卷积层的计算和内存开销随序列长度线性增长,显著降低 KV 缓存需求,使预填(prefill)速度提升数倍。
- GQA 优化:在关键的注意力层采用分组查询注意力,保持全局语义感知的同时进一步削减计算量。
稀疏 MoE 高效激活
- 总参数 24 B,但每个 token 仅激活约 2.3 B 参数,采用稀疏专家(Mixture of Experts)机制。
- 内存需求:活跃参数路径仅需 32 GB 显存,可在高端笔记本、集成 GPU(iGPU)或 NPU 上本地部署,无需数据中心级别的 A100。
- 能耗优势:相当于 2 B 参数模型的推理延迟与能耗,却拥有 24 B 模型的知识密度。
基准测试表现
| 项目 | LFM2‑24B‑A2B | Qwen3‑30B‑A3B | Snowflake gpt‑oss‑20b |
|---|---|---|---|
| GSM8K 逻辑推理 | 与 48 B 密集模型持平 | 略低 | 低于 24 B |
| MATH‑500 | 超越 2 倍规模模型 | 略逊 | 明显落后 |
| 吞吐量 (单 H100) | 26.8K token/s(1,024 并发) | 约 20K | 约 15K |
- 长上下文:支持 32k token 的上下文窗口,适用于隐私敏感的 RAG 场景与本地文档分析。
边缘部署价值
- 硬件兼容:原生支持 llama.cpp、vLLM、SGLang、MLX 等开源推理框架。
- 开放许可:采用 LFM Open License v1.0,模型权重可自由下载与二次开发。
- 生态潜力:在消费级硬件上实现大模型推理,为企业降低部署成本、加速 AI 应用落地提供了可行路径。
行业意义
Liquid AI 的这一步表明,模型规模不再是唯一的竞争维度。通过混合注意力‑卷积与稀疏专家设计,能够在保持推理质量的前提下降低算力和内存需求,为下一代 边缘大模型 铺平道路,也为 Open‑Source 社区提供了新的架构参考。
“我们希望让每一台普通笔记本都能跑起 24 B 级别的语言模型,”Liquid AI 首席科学家在博客中写道。
整体来看,LFM2‑24B‑A2B 以其 高效混合架构、稀疏激活和开放生态 三大优势,挑战了传统大模型对算力的依赖,预示着生成式 AI 正向更低成本、更广覆盖的方向演进。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。