阿里巴巴Qwen 3.5中型系列实现高效推理,35B模型凭3B激活参数超越235B
•17 阅读•3分钟•前沿
LLMAgent阿里Qwen 3.5
•17 阅读•3分钟•前沿
技术突破
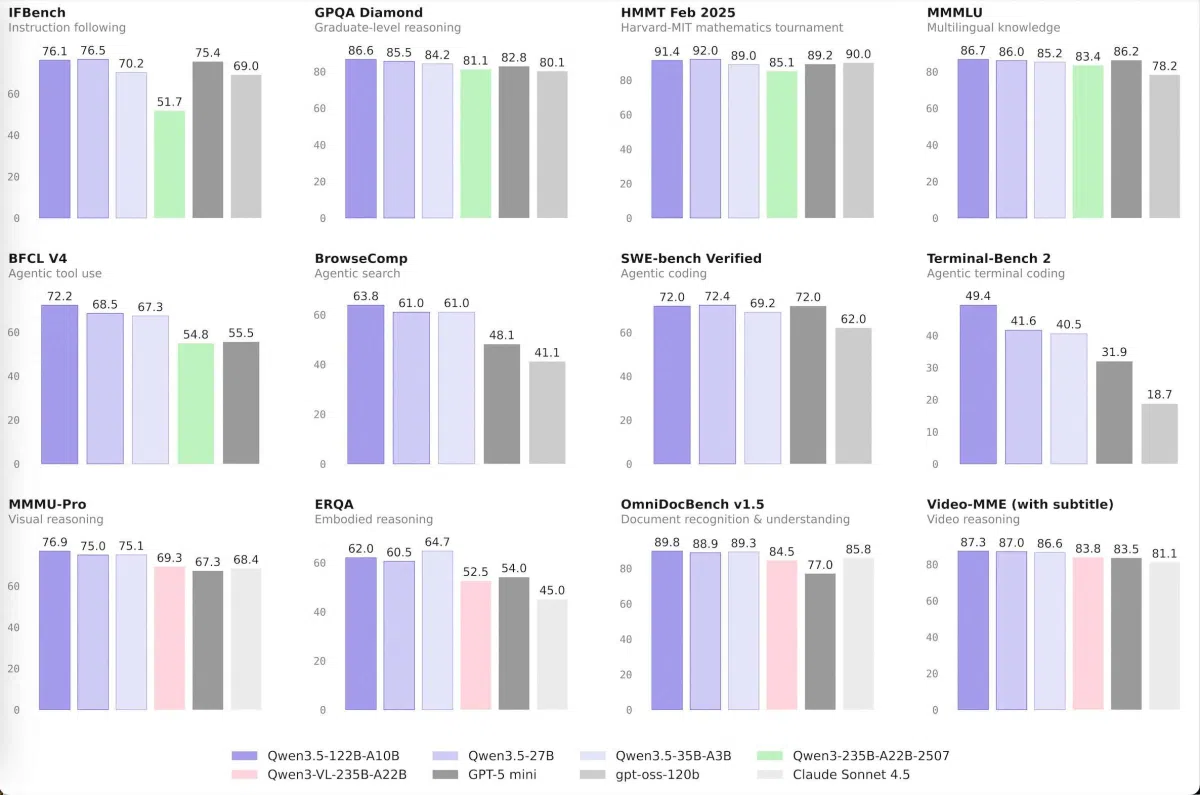
Qwen 3.5系列的核心理念是“更小更强”。团队采用Mixture‑of‑Experts(MoE)混合专家架构,将总参数量与实际推理时激活的参数量解耦。
- A3B 设计:35 B模型在整体上拥有350亿参数,但推理时仅激活30亿(A3B),实现了算力与性能的双重提升。
- Gated Delta Network + Gated Attention:混合线性注意力与传统注意力块,使解码吞吐量大幅提升,显存占用下降。
- 强化学习(RL)+ 长链思维(CoT):四阶段后训练流程让模型在多步推理、代码生成等复杂任务上保持逻辑一致性。
关键模型概览
| 模型 | 总参数 | 激活参数 | 主要定位 |
|---|---|---|---|
| Qwen3.5‑35B‑A3B | 35 B | 3 B | 通用高性能 |
| Qwen3.5‑Flash | 35 B‑A3B(部署版) | 3 B | 低延迟生产 |
| Qwen3.5‑122B‑A10B | 122 B | 10 B | 代理型任务 |
| Qwen3.5‑27B | 27 B | 2.7 B | 轻量化部署 |
生产化特性
- 1M 上下文窗口:默认支持百万级 token,省去复杂的检索‑增强(RAG)切分流程,适用于全库代码审查或大文档摘要。
- 原生工具调用:模型内置函数调用与 API 接口,可直接与数据库、云服务交互,降低 Prompt Engineering 成本。
- 低延迟部署:Qwen3.5‑Flash 经过专门的高吞吐量调优,适配标准 GPU(A100、H100)甚至中端卡,实现企业级 SLA。
行业影响
Qwen 3.5的出现向业界证明,算力密度而非盲目扩容才是下一代大模型的关键。35 B模型以3 B激活参数跑赢前代 235 B模型,意味着中小企业无需投入数十亿美元算力即可获得接近前沿的推理能力。
- 成本压缩:在同等推理质量下,算力需求下降约 80%,大幅降低云租赁费用。
- 本地化部署:1M 上下文与相对轻量的激活参数让模型可以在私有云或边缘服务器上运行,符合数据合规要求。
- 生态加速:原生工具支持为 Agent 应用提供即插即用的能力,推动企业级 AI 助手、自动化运维等场景快速落地。
"Qwen 3.5 让我们看到了‘小模型也能玩转前沿任务’的可能,这对国产大模型生态是一次重要的信号。"——阿里巴巴技术副总裁
展望
随着算力成本的进一步下降和数据质量的提升,MoE‑plus‑RL 的组合有望成为大模型研发的标准路径。Qwen 3.5系列已在多家互联网企业和金融机构进行试点,未来可能扩展到自动化营销、代码生成和多模态检索等更广阔的业务场景。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。