Google提出深思比率显著提升LLM准确率并削半推理成本
•26 阅读•4分钟•前沿
GoogleDeepSeekQwenDeep-Thinking RatioThink@n
•26 阅读•4分钟•前沿
背景
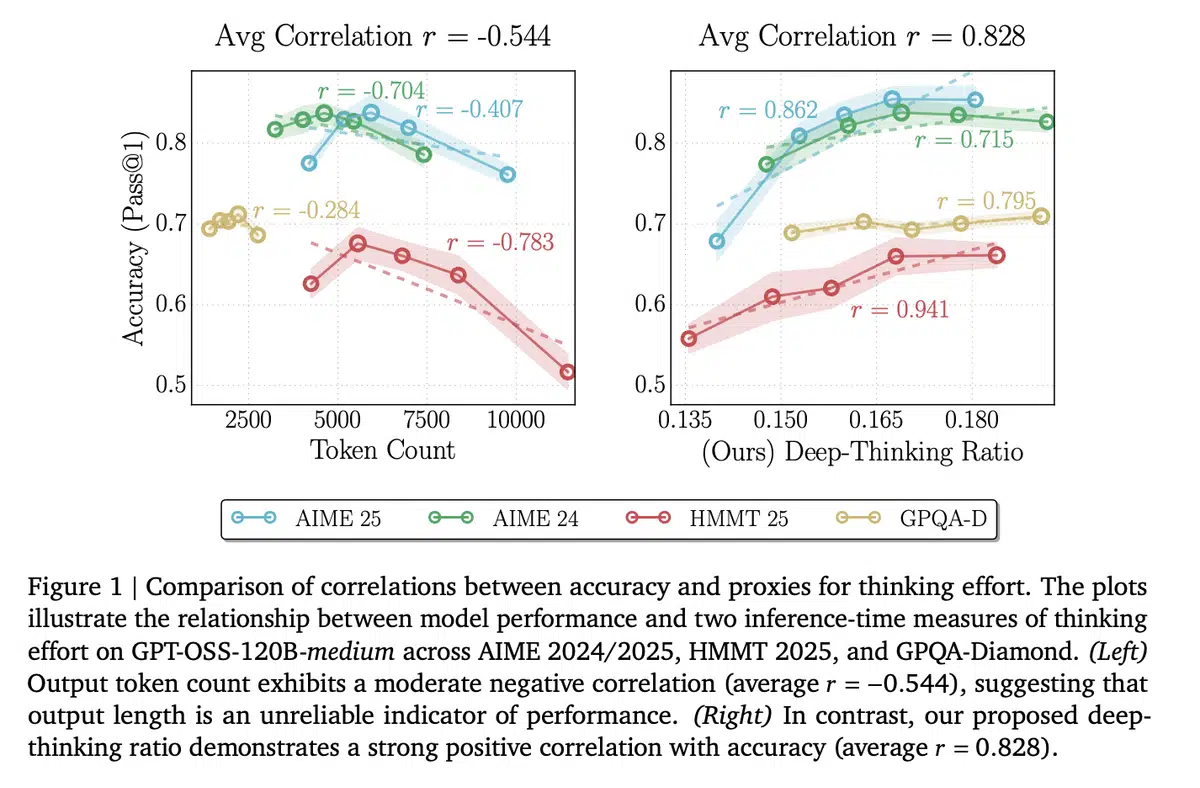
过去几年,提升大语言模型 (LLM) 推理质量的常用做法是延长 Chain‑of‑Thought (CoT) 的推理长度,认为“说得越多”代表“思考得越深”。Google 与弗吉尼亚大学的最新研究打破了这一认知,指出仅靠 token 数并不能反映模型真实的思考力度,甚至会导致“过度思考”而降低准确率。
深思比率的测量方法
- 深思 token 定义:模型在较浅层 (如第 5 层) 预测已基本稳定的 token 被视为 浅层 token;而在更深层 (如第 30‑36 层) 才收敛的 token 则被标记为 深思 token。
- 层级内部投影:研究者使用模型的未嵌入矩阵 (unembedding matrix) 将每层隐藏状态投射到词表空间,得到每层的概率分布
pt,l。 - Jensen‑Shannon 距离:计算每层分布与最终层分布
pt,L的 Jensen‑Shannon Divergence (JSD),记为Dt,l。 - 深思比率 (DTR):若 token 在后 15% 的层才收敛 (
ρ = 0.85),则计为深思 token。整段文本的 DTR 为深思 token 所占比例。
“深思比率能够捕捉模型内部的迭代过程,提供比单纯长度更可靠的思考强度信号。” — 论文第一作者
Think@n 推理加速方案
传统的 Self‑Consistency (Cons@n) 需要对同一道题生成 dozens of 完整答案,然后进行多数投票,计算成本极高。Think@n 引入 早停机制:
- 为每个候选答案生成前 50 个 token 的前缀。
- 依据前缀的 DTR 快速评估其思考深度。
- 直接终止 DTR 低于阈值的候选,仅完成高 DTR 候选的后续生成。
这种方式在保证或提升答案质量的同时,将总 token 消耗从 307.6k 降至 155.4k,成本下降约 49%。
实验结果与意义
| 方法 | 准确率 | 平均成本 (k tokens) |
|---|---|---|
| Cons@n (多数投票) | 92.7% | 307.6 |
| Think@n (DTR 选拔) | 94.7% | 155.4 |
- 负相关的长度:原始 token 长度与准确率的相关系数为
r = -0.59,说明更长的推理往往伴随错误累积。 - 正相关的 DTR:跨模型(DeepSeek‑R1‑70B、Qwen3‑30B‑Thinking、GPT‑OSS‑120B)平均相关系数
r = 0.683,显示 DTR 与准确率呈显著正向关系。 - 成本效益:仅凭 50 token 前缀即可估算深度,提前剔除低效样本,实现近乎“一半算力”的节约。
业界影响
- 模型评估新范式:DTR 为 LLM 推理提供了更细粒度的内部信号,未来可能被集成进主流推理框架与 API。
- 算力成本优化:在云服务与大模型即服务 (MaaS) 场景下,Think@n 可帮助厂商显著降低计费成本,提高用户体验。
- 研究方向延伸:该工作激发了对 层级内部表征 与 动态推理调度 的进一步探索,或促成更智能的自适应推理策略。
综上,深思比率为大模型推理提供了“思考深度”度量,Think@n 则把这一度量转化为实际的成本节约与性能提升,预示着 LLM 推理进入以质量为核心的精细化时代。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。