Tavus发布Phoenix-4实现亚秒级实时情感视频生成
•25 阅读•3分钟•前沿
文生视频TavusPhoenix-4Gaussian-Diffusion
•25 阅读•3分钟•前沿
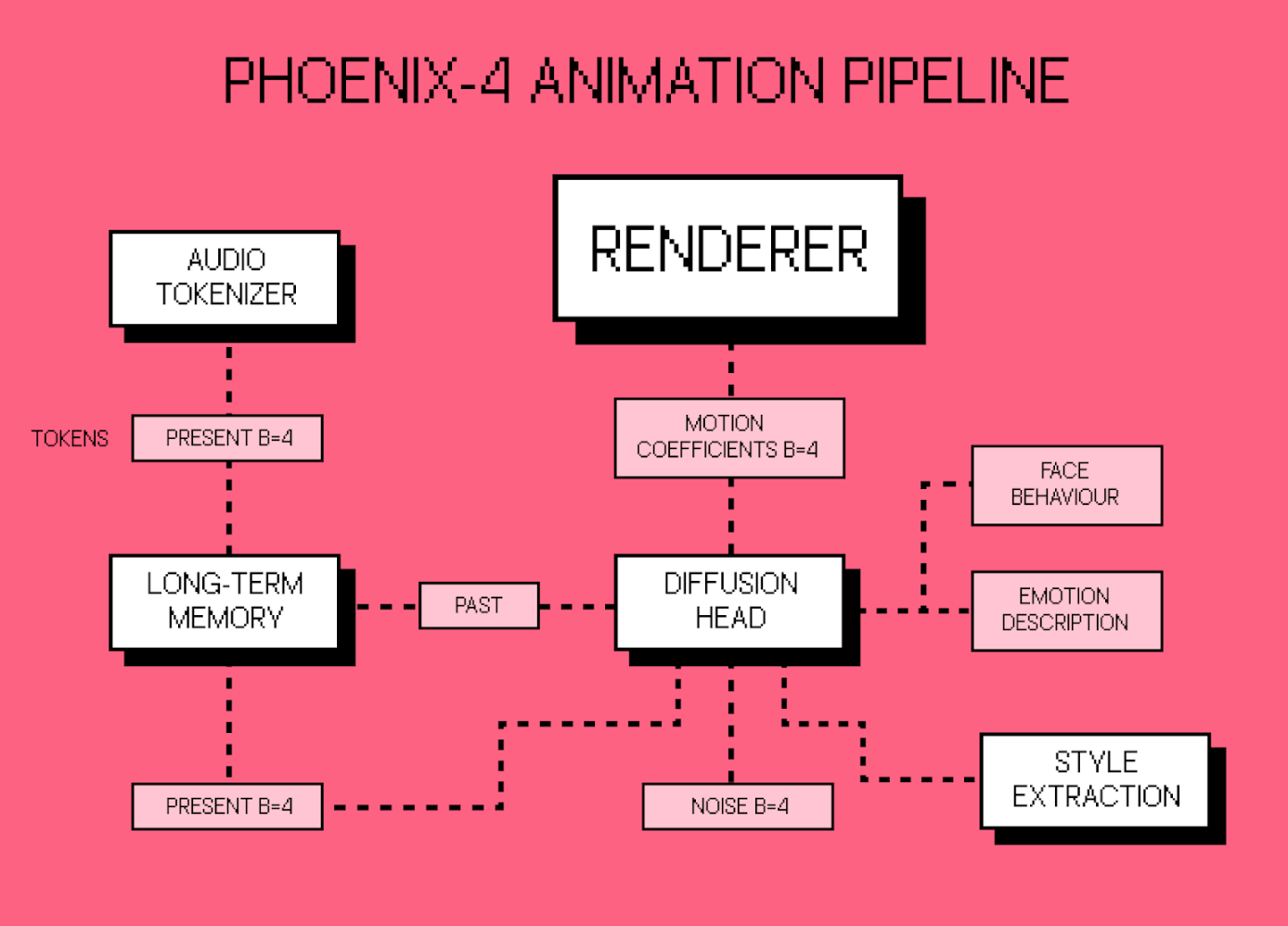
背景与意义
生成式视频一直受制于“恐怖谷”——画面虽逼真,却缺乏自然的情感交互。Tavus 将焦点从单纯的口型同步转向整体的人类感知,推出面向实时对话的视频模型 Phoenix-4,力图让数字人具备与人类相匹配的情绪与时序感。
技术核心
-
三模架构:
- **Raven-1(感知)**负责解析用户的面部表情与语音语调,提取情绪向量;
- **Sparrow-1(时序)**决定对话的中断、停顿与接续时机,确保交互自然流畅;
- **Phoenix-4(渲染)**是核心的高保真视频合成引擎,使用 Gaussian‑Diffusion 取代传统 GAN,实现微表情与皮肤光照的空间一致性。
-
Gaussian‑Diffusion 渲染:该模型在每帧生成时考虑光照变化、皮肤拉伸等细微因素,使得头部转动或眨眼时纹理保持稳定,显著降低了“僵硬感”。
超低时延实现
Phoenix-4 采用 stream‑first 架构,结合 WebRTC 直接在浏览器端逐帧推送视频数据,避免先生成完整文件再播放的瓶颈。整个从用户发声到数字人呈现的链路控制在 600 ms 以下,满足实时对话对时延的苛刻要求。
程序化情感控制
平台提供 Emotion Control API,开发者可在请求体中指定 emotion 参数(joy、sadness、anger、surprise)。系统依据情绪向量调节面部几何,生成符合情感的微笑、皱眉等细节,实现条件式视频生成。
快速复制训练
创建自定义数字人(Replica)仅需 2 分钟 视频素材。训练完成后可通过 Tavus CVI SDK 的 POST /conversations 接口启动会话,使用返回的 WebRTC URL 嵌入前端即可实时渲染。
市场与前景
凭借亚秒级时延和细腻情感表现,Phoenix-4 可广泛用于客服、在线教育、虚拟主持人等交互场景。其开放的 API 与轻量化训练流程也为中小企业提供了低成本进入数字人市场的通道。
“我们希望通过技术让机器不再只是说话机器,而是真正能‘感受’并回应人类情绪的数字伙伴。”——Tavus 首席技术官
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。