Kyutai推出Hibiki‑Zero 同时语音翻译模型实现零对齐数据突破
•62 阅读•3分钟•前沿
KyutaiHibiki-Zero语音翻译GRPO
•62 阅读•3分钟•前沿
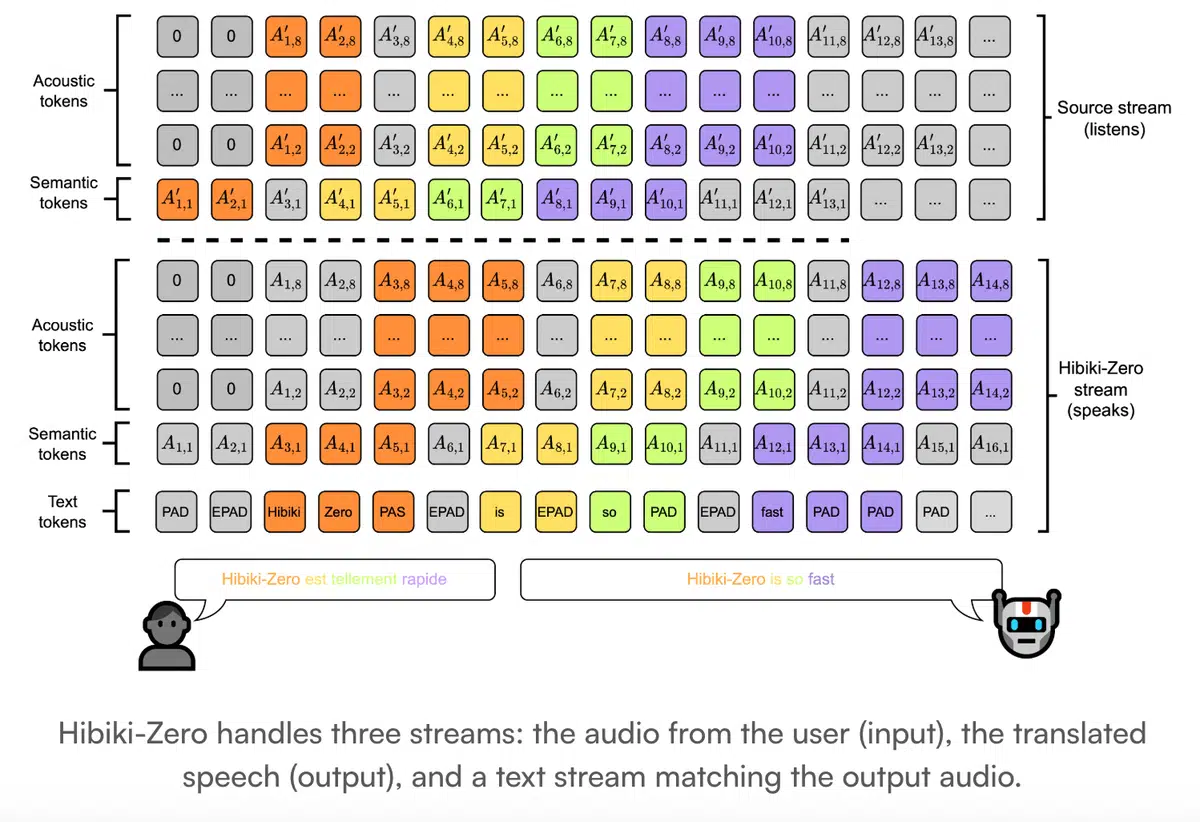
模型概览
Kyutai最新发布的 Hibiki‑Zero 是一款3B参数的同步语音翻译模型,支持 语音‑到‑语音 (S2ST) 与 语音‑到‑文本 (S2TT) 双向实时翻译。模型的核心创新在于彻底摆脱了传统的词级对齐数据需求,采用 Group Relative Policy Optimization (GRPO) 强化学习策略,实现了翻译时延的自动优化。
多流架构与技术细节
- 解码器‑Only 多流设计:模型同时处理三条流——源音频流、目标音频流以及用于对齐的内部文本流。
- 音频编码:采用因果流式音频编解码器 Mimi,以12.5 Hz 的帧率将波形离散为令牌。
- Transformer 核心:使用 RQ‑Transformer,包含 28 层时序 Transformer(隐藏维度 2048)和 6 层深度 Transformer(隐藏维度 1024)。
- 规模与容量:参数总量 3 B,支持 4 分钟的上下文窗口,配备 16 层高保真音频码本。
训练流程与 GRPO 强化学习
Hibiki‑Zero 的训练分为两阶段:
- 粗对齐训练:利用句级对齐数据,让模型学习基本的跨语言映射,并在目标语音中人为插入静音以模拟非单调依赖。
- GRPO 强化学习:在此阶段仅依据 BLEU 分数设定奖励,模型通过多点奖励机制自行学习何时发声、何时倾听,α 超参数调节时延‑质量权衡。
性能评估与对标
在 Audio‑NTREX‑4L 长句基准上,Hibiki‑Zero 在五种 X‑to‑English 任务中取得领先:
- 法语任务 ASR‑BLEU 28.7(对比 Seamless 23.9)
- 说话人相似度 61.3(对比 44.4)
- 平均时延 LAAL 2.3 s(对比 6.2 s)
在 Europarl‑ST 短句基准中,模型实现 ASR‑BLEU 34.6,时延仅 2.8 s,且在自然度与声纹保持方面显著优于已有系统。
行业意义与未来展望
Hibiki‑Zero 的零对齐数据需求意味着在新增语言时只需少量句级数据即可快速迁移。实验表明,使用不足 1,000 h 的意大利语语料即可达到与主流系统相当的质量与时延,这为低资源语言的实时翻译打开了可行路径。
该模型的发布不仅展示了强化学习在同步翻译中的实用性,也为后续 多模态交互、实时会议翻译 等场景提供了技术底座。随着更多语言的快速适配,Hibiki‑Zero 有望在跨语言协作、国际媒体转播以及无障碍服务等领域产生广泛影响。
“摆脱词级对齐的束缚,是同步语音翻译向大规模多语言扩展的关键一步。”——Kyutai 研发团队
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。