OpenAI发布GPT‑5.3 Codex‑Spark实现15倍提速千标记每秒
•30 阅读•3分钟•前沿
OpenAICerebrasCodexGPT-5.3Wafer-Scale Engine
•30 阅读•3分钟•前沿
关键亮点
- 15倍提速:相较于旗舰 GPT‑5.3 Codex,Spark 每秒可生成超过 1000 标记,实现近实时代码输出。
- 硬件创新:首次在 Cerebras Wafer‑Scale Engine 3(WSE‑3)上运行,单芯片规模消除 GPU 集群间的通信瓶颈。
- 低时延通信:采用持久化 WebSocket 连接,将往返时延降低约 80%,首标记延迟缩短 50%。
硬件驱动
Cerebras 的 WSE‑3 是一块与硅晶圆同尺寸的芯片,拥有数百 GB 的片上内存和极高带宽。模型完整驻留在单芯片上,避免了传统多 GPU 集群的互联延迟,使得每个 token 的计算几乎是瞬时完成。
软件优化
OpenAI 对模型的请求协议进行重构,放弃传统的 HTTP‑POST 轮询,改为持续的 WebSocket 流。此举带来了:
- 每 token 开销下降 30%;
- 实时中断:开发者可以在模型输出途中即时干预,重新指令而无需等待完整代码块。
性能与局限
| 项目 | Spark | GPT‑5.3 Codex(旗舰) |
|---|---|---|
| 速度 | 1000+ token/s | ~70 token/s |
| 推理深度 | 较浅 | 深度推理 |
| 安全评级 | 未达 “High” | High |
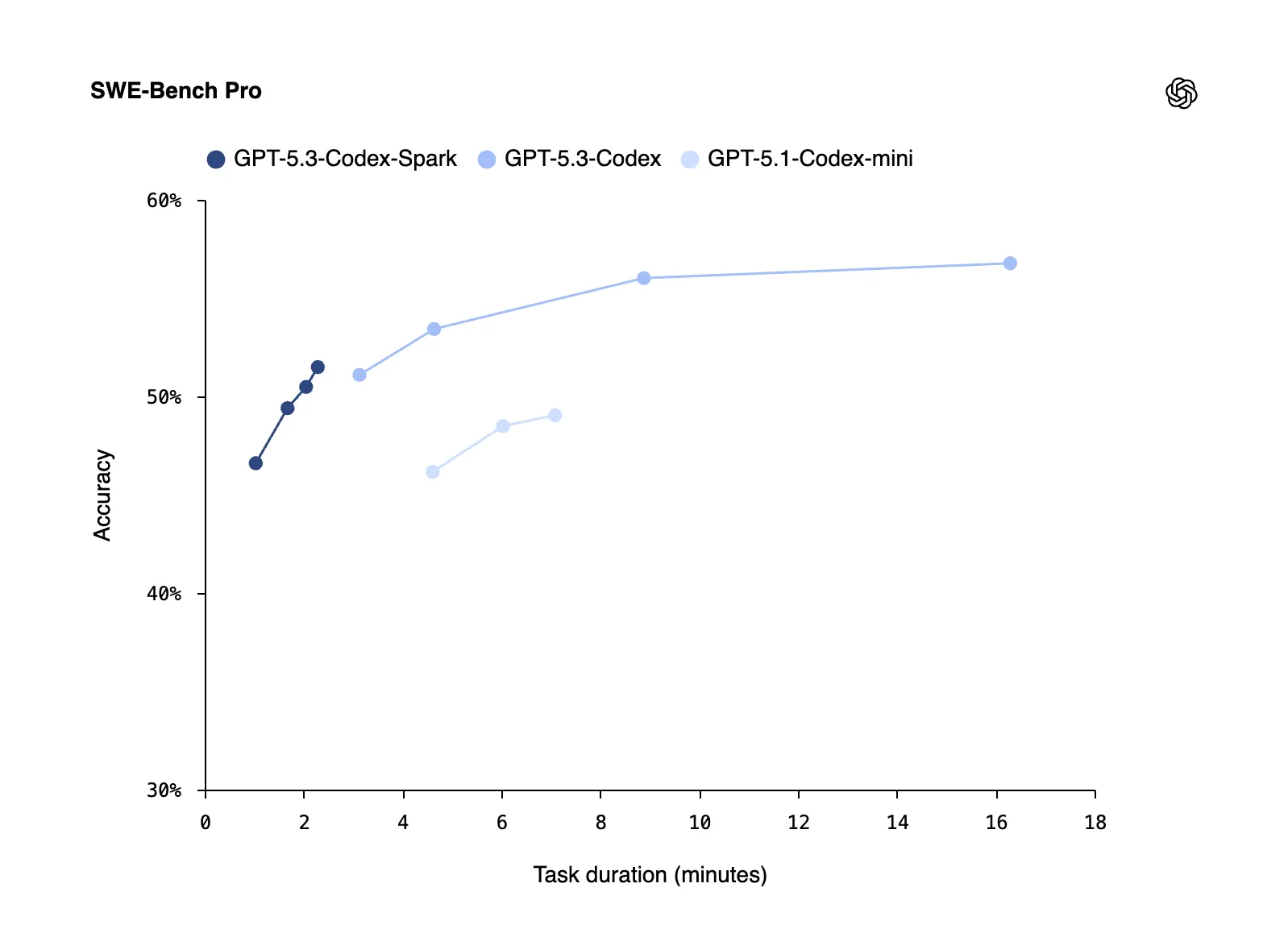
| 基准表现 | SWE‑Bench Pro、Terminal‑Bench 2.0 低于旗舰 | 领先 |
由于模型规模被压缩,Spark 在复杂多文件重构和安全敏感代码生成方面表现不佳,OpenAI 明确建议在此类场景仍使用旗舰模型。
使用方式
- ChatGPT Pro:在模型选择器中切换至 “Spark”。
- VS Code 扩展:直接在插件中指定
gpt-5.3-codex-spark。 - CLI:
codex --model gpt-5.3-codex-spark。
“如果你的开发工作流以微迭代为主,Spark 能把思考与实现的间隔压到毫秒级。”——OpenAI 官方声明
总体来看,GPT‑5.3 Codex‑Spark 通过硬件‑软件协同实现了前所未有的代码生成速度,为实时 Pair‑Programming 提供了技术基座,但在深度推理和安全保障方面仍需依赖旗舰模型。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。