智能体生产监控全链路揭秘,对话追踪与自动评估并行提升
•25 阅读•4分钟•应用
LLMLangSmithAgent
•25 阅读•4分钟•应用
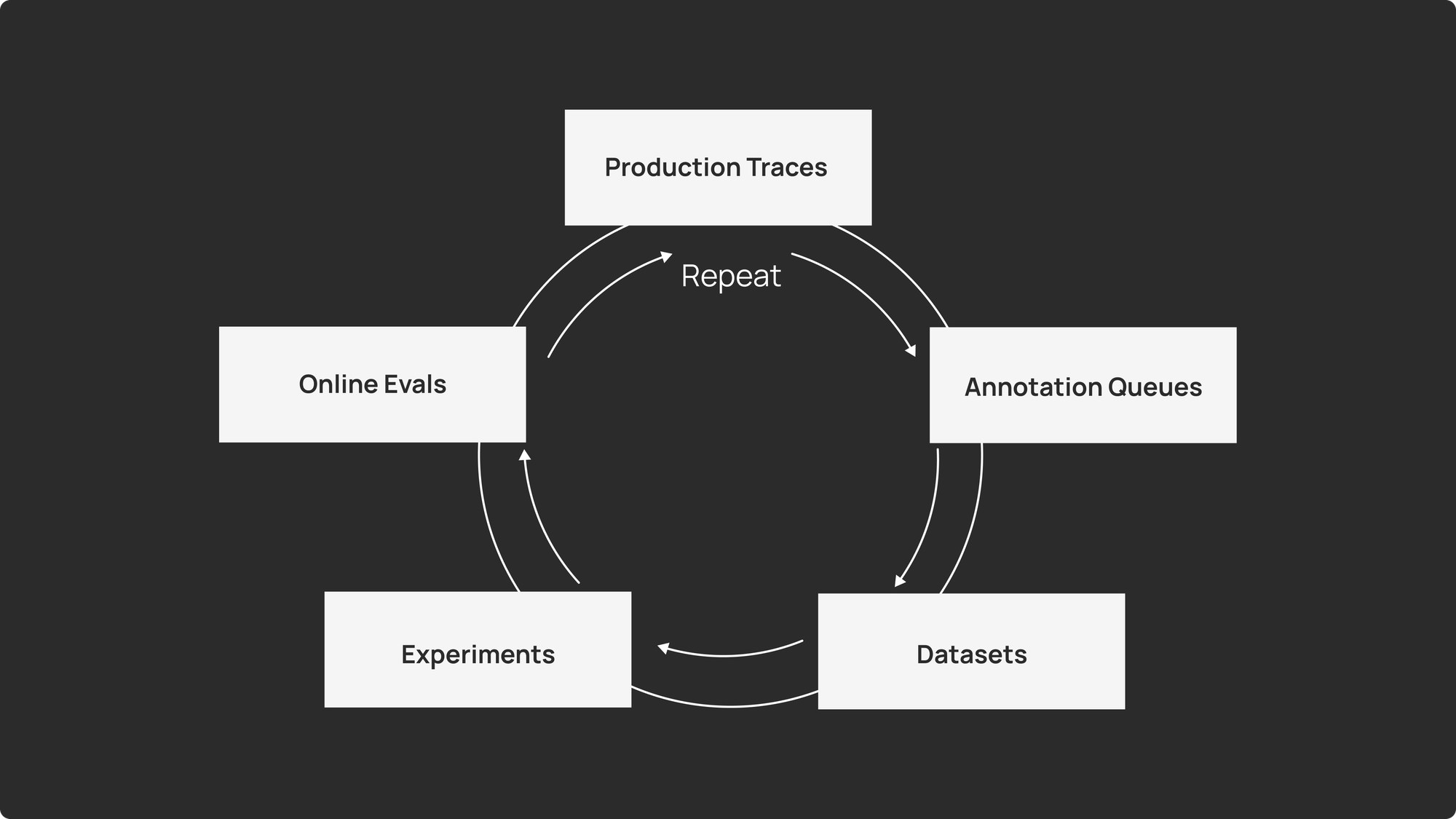
生产环境与传统软件的根本差异
传统软件的交互路径固定,测试覆盖率可达 80%‑90%。监控重点集中在错误率、响应时延等系统指标。而智能体接受的是自然语言,输入空间无限,模型对微小提示变化极度敏感,往往会出现同一请求的不同输出。因此,仅靠传统 APM 无法捕捉真实的质量问题。
必须监控的核心维度
- 完整的 Prompt‑Response 对:记录用户原始提问及模型返回内容,便于回溯问题根源。
- 多轮上下文:将关联的多轮对话聚合为一次会话,分析整体走向。
- 轨迹与中间步骤:智能体常通过工具调用、检索等多步推理完成任务,需要对每一步的输入、输出进行可视化审计。
这些信息远超单一的 HTTP 状态码,构成了真正的质量信号。
人工评审的规模化难题
人工审查能够判断响应是否有帮助、语气是否恰当、信息是否安全,但在生产环境下,日均上千甚至上万次交互的审查成本极高。为此,业界常用两种互补手段:
1. 注释队列(Annotation Queues)
- 有针对性抽样:仅将负面反馈、异常高成本调用或特定时间窗口的会话送入队列。
- 结构化评审:预设评价维度(相关性、正确性、语气、合规性),让评审者快速打分。
- 闭环反馈:标注结果可直接回流至训练数据或评估集,实现快速迭代。
2. LLM 代理评估(LLM‑as‑Judge)
- 自动化质量指标:如连贯性、信息完整度等无需参考答案的指标。
- 安全合规检测:实时拦截敏感信息泄露或政策违规。
- 格式校验:确保输出满足业务约定的结构化要求。
LLM 评估的优势是规模大、延迟可接受(批处理或抽样),但仍需注意模型漂移、成本以及与人工标注的一致性问题。实践中,往往将两者结合:大比例使用 LLM 快速筛选,随后对高危或异常样本进行人工复核。
LangSmith 的全链路观测方案
LangSmith 将上述思路落地为一套可操作的产品功能:
- Insights Agent:基于自动聚类的使用模式与错误模式发现,引导产品经理快速定位用户最常用的功能或常见失败点。
- 在线评估(Online Evaluations):可配置抽样比例、评估维度和阈值告警,实现质量趋势的实时监控。
- 自定义仪表盘与警报:支持业务关键指标(如任务完成率、用户满意度)以及技术指标(工具调用成功率、成本/时延)并行展示,满足跨团队协作需求。
为什么通用 APM 难以胜任
- 负载与存储:完整的对话日志在高并发下需要 PB 级存储,并且需要语义搜索能力。
- 数据模型不匹配:传统日志以结构化数值为主,难以直接支撑多轮上下文的关联查询。
- 团队角色差异:智能体监控的使用者从 SRE 扩展到 AI/ML 工程师、产品经理、领域专家,工具必须支持协作与可视化,而非单纯的系统健康监控。
结语
智能体在生产环境中的监控核心已从“系统是否崩溃”转向“对话本身是否达标”。通过注释队列与 LLM 评估的双轨机制,结合 LangSmith 的自动聚类与实时评估功能,团队能够在海量生产数据中快速发现问题、闭环修复,并持续提升用户体验。未来的挑战仍在于评估模型的准确性、成本控制以及合规隐私的平衡,值得业界持续关注。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。