Google推出Gemini安卓自动化功能 助力多步任务一键完成
•22 阅读•3分钟•应用
GoogleGeminiAndroidPixel
Sarah Perez••22 阅读•3分钟•应用
关键更新
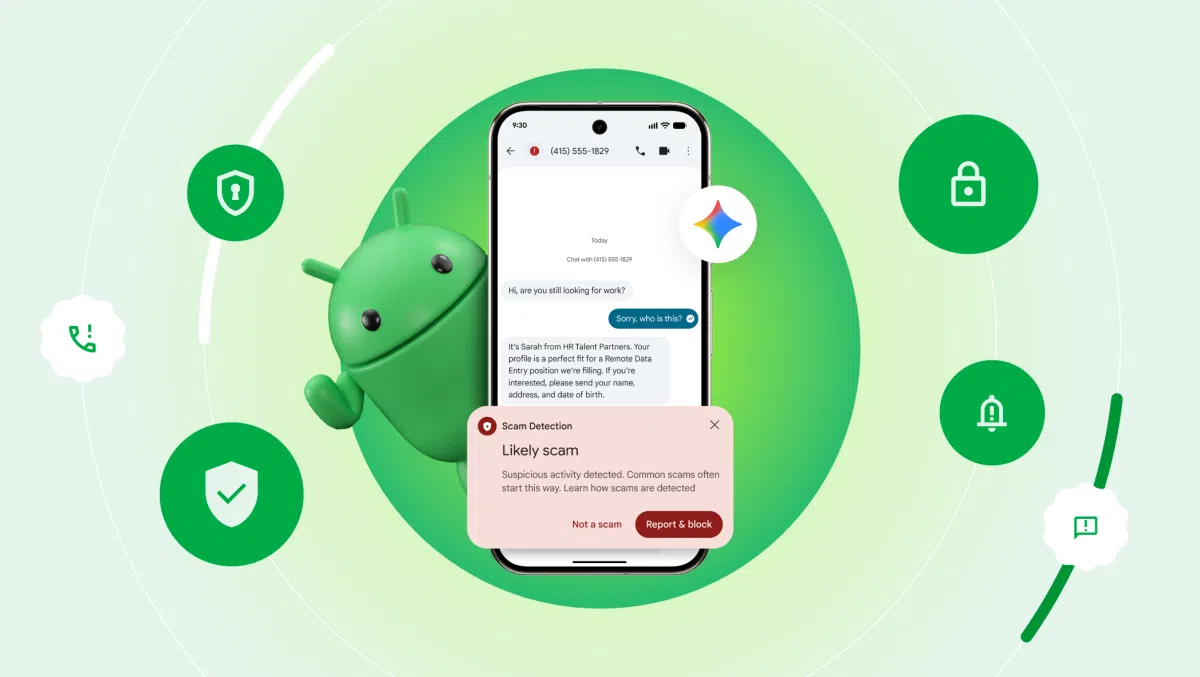
Google本周在Android系统上为Gemini AI推出全新自动化功能,允许用户通过语音或文字指令让模型在手机上完成多步骤任务,例如叫车、外卖或杂货配送。该功能目前处于Beta阶段,首批支持Pixel 10、Pixel 10 Pro以及Samsung Galaxy S26系列,并仅在美国和韩国提供。
功能细节
- 多步任务编排:Gemini能够识别用户的完整需求,自动在对应的第三方APP中完成下单、支付、确认等环节,无需用户逐项操作。
- 支持的场景:目前覆盖乘车服务(Uber、Lyft 等)、外卖平台(DoorDash、Uber Eats)以及超市配送(Instacart、Walmart Grocery)。
- 设备与系统要求:仅在Gemini专属App内可用,且需要搭载最新的Android 14系统以及Google的On‑device模型。
- 地域限制:初期仅面向美国和韩国市场,后续将根据监管和合作伙伴关系逐步扩展。
安全与隐私措施
- 显式授权:所有自动化任务必须在用户明确发出指令后才会启动,系统会在任务执行过程中实时展示进度,用户可随时中止。
- 受限访问:Gemini运行在受保护的虚拟窗口中,仅能调用已授权的目标APP,无法读取手机其他数据。
- 防误操作:若模型检测到异常或冲突,会自动暂停并提示用户确认,降低误下单或支付风险。
市场影响与竞争格局
此举标志着生成式AI从内容创作向真实生活事务执行迈出重要一步。与OpenAI的ChatGPT插件、Anthropic的Claude Cowork以及OpenClaw等已有的跨平台自动化方案相比,Google凭借Android生态的深度整合和自研On‑device模型,具备更低延迟和更强隐私保障。短期内,预计将推动Android用户对AI助手的使用频率提升,并可能促使竞争对手加速在移动端推出类似功能。
展望
Google表示,未来将扩大支持的应用类别和设备范围,并计划在欧洲和亚洲其他地区逐步上线。随着AI模型能力的提升和合作伙伴生态的成熟,Gemini在移动端的自动化有望演化为全方位个人助理,进一步模糊人机交互的边界。
“我们希望让AI真正成为用户日常生活的可靠助手,而不是仅限于文字对话。”——Google AI负责人
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。