Exa AI推出Exa Instant实现亚200毫秒搜索 加速AI代理实时推理
•44 阅读•3分钟•应用
RAGAgentic AIExa AIExa Instant
•44 阅读•3分钟•应用
背景与需求
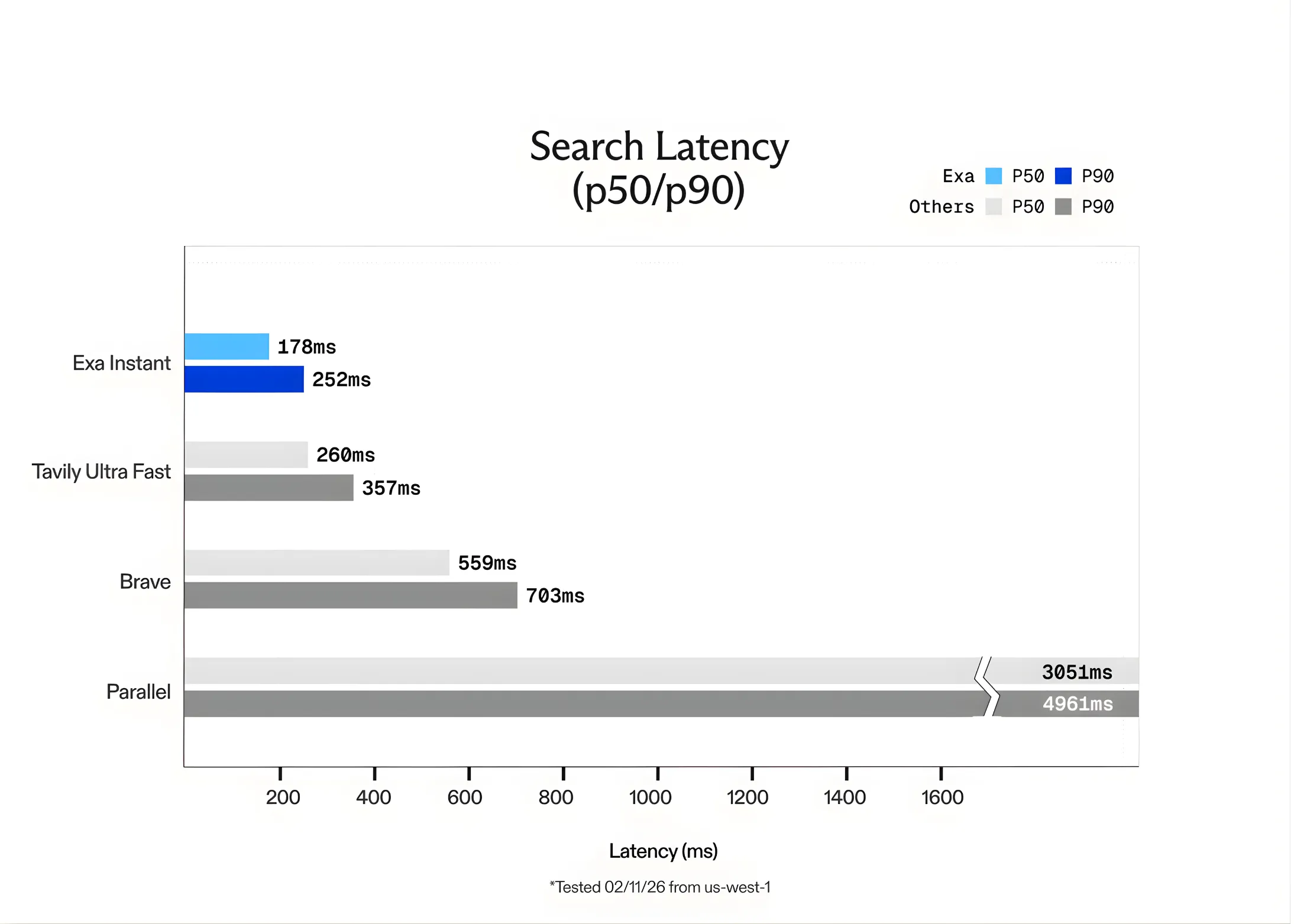
在大语言模型(LLM)应用中,检索阶段的延迟往往成为整体响应的瓶颈。传统搜索 API 通过包装 Google、Bing 等搜索引擎,额外耗时 700‑1000ms,使得多轮代理任务的执行时间急剧上升。Exa AI 将焦点放在“速度即服务”,推出专为 AI 代理优化的 Exa Instant,以亚200ms 的响应时间重新定义 RAG 流程。
核心技术优势
- 端到端神经检索堆栈:从爬虫、向量化到推理全部自研,避免了第三方包装层的额外开销。
- 语义嵌入+Transformer:不再依赖关键词匹配,而是通过查询嵌入捕捉意图,实现更高的相关性。
- 网络延迟最小化:美国西部(加州)区域的基准测试显示网络往返约 50ms,整体响应保持在 100‑200ms 区间。
性能基准对比
Exa 团队使用 SealQA 数据集并为每条查询随机添加 GPT‑5 生成的噪声词,以防缓存。对比结果如下:
- Tavily Ultra Fast:平均响应约 1.2s,Exa Instant 快 12‑15 倍。
- Brave API:平均 900ms,Exa Instant 仍保持约 10‑13 倍优势。
- 自研 Exa Fast / Exa Auto:虽在准确性上更强,但响应分别为 300ms 与 500ms,仍高于 Exa Instant。
定价与开发者集成
- 费用:$5 / 1,000 次请求,定位为低成本的检索原语。
- 接入方式:通过 dashboard.exa.ai 提供的 RESTful API,返回清洗后的 HTML、Markdown 以及高亮片段,直接供 LLM 读取,无需额外爬虫或清洗代码。
- 兼容性:支持主流 LLM 框架(OpenAI、Claude、Gemini 等),可无缝嵌入现有 RAG 流程。
市场与行业影响
Exa Instant 的出现为 AI 代理提供了“实时检索”能力,使得复杂任务(如多步推理、动态规划)能够在单次思考循环内完成多次搜索,而不会引入可感知的延迟。对于企业级 SaaS、聊天机器人以及自动化工作流平台,这意味着用户体验将接近即时响应,进而提升产品黏性。与此同时,低价位的计费模式也降低了检索成本门槛,可能促使更多中小开发者在产品中加入 RAG 功能,进一步加速生成式 AI 的生态繁荣。
“搜索不再是瓶颈,AI 代理可以真正做到‘思考即搜索’。” — Exa AI 官方博客
未来,随着模型规模继续提升与硬件算力加强,Exa AI 计划在保持亚200ms 响应的前提下,进一步提升检索准确度,打造兼具速度与质量的全栈搜索解决方案。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。