Microsoft发布VibeVoice‑ASR 实现单次处理60分钟长音频
•41 阅读•3分钟•开源
开源MicrosoftASRVibeVoice-ASR
•41 阅读•3分钟•开源
发布概览
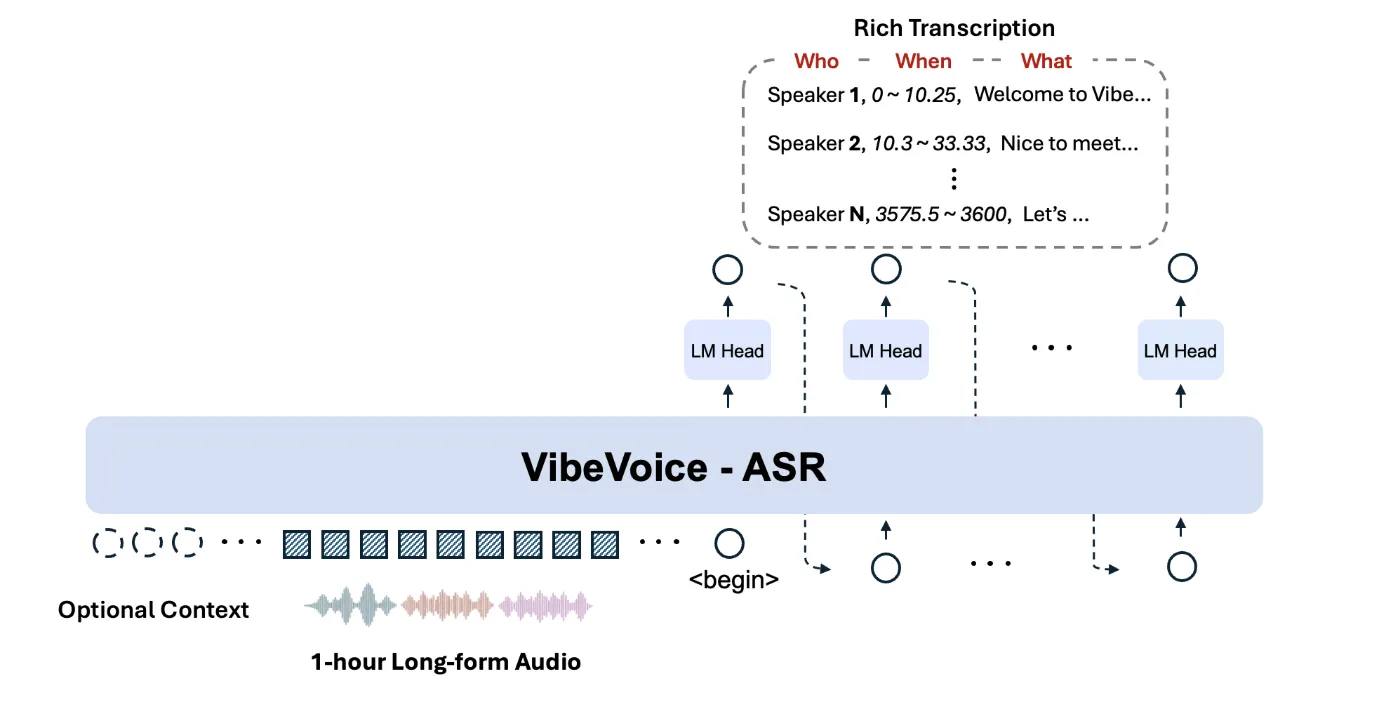
Microsoft今日正式开源VibeVoice‑ASR,作为VibeVoice系列首个统一的语音转文字模型,采用MIT许可证发布。模型一次性接受最长60分钟、约64K token的音频输入,保持全局上下文,直接输出包含说话人、时间戳和文本的结构化转录。
关键特性
- 单次全程处理:无需切片或后处理,模型在单一推理步骤内完成整段音频的识别与对话者分离,适用于会议、讲座和长呼叫等场景。
- 自定义热词:用户可在推理时注入产品名、机构名等专业词汇,模型会在解码阶段倾向正确拼写与发音,无需重新训练。
- 结构化输出:转录结果同时提供说话人标识、时间戳以及文本内容,便于后续的摘要、行动项提取或分析仪表盘直接使用。
- 开源完整生态:仓库中同时提供文本到语音(TTS)和实时语音合成模型,配套LoRA微调脚本支持轻量适配与深度领域定制。
技术细节
VibeVoice‑ASR基于连续语音标记器(7.5 Hz)和下一标记扩散框架构建。大语言模型负责文本与对话推理,扩散头负责细粒度声学细节生成。通过单一全局上下文,模型在长音频中维持说话人身份和主题连贯性,显著降低传统ASR的段落切割误差。
评估指标包括DIAR(说话人分割错误率)、cpWER 与 tcpWER(对话场景下的词错误率),在多说话人长音频基准上表现领先,特别适配会议记录和多方通话场景。
业界影响
- 提升企业会议自动化:统一模型简化了会议记录、实时字幕和后期摘要的技术栈,降低部署成本。
- 加速行业定制:热词与LoRA微调让同一模型可快速适配金融、医疗、教育等专业领域。
- 推动开源语音技术生态:MIT许可证鼓励社区贡献模型权重、工具链和评测基准,进一步缩小商业闭源与学术开源之间的差距。
"VibeVoice‑ASR 的出现标志着长时段语音识别进入了全局上下文时代,未来的语音 AI 将更懂场景、更懂人。" — Microsoft AI 团队
结语
作为微软在生成式语音领域的最新里程碑,VibeVoice‑ASR 将长音频识别的技术瓶颈进一步打破。凭借单次全程处理、自定义热词和结构化输出三大核心能力,它为企业级语音应用提供了更简洁、更高效的解决方案,也为开源社区注入了强劲的创新动力。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。